1.2. 从批处理到流处理#
数据与数据流#
在大数据的 5 个 “V” 中我们已经提到,数据量大且产生速度快。从时间维度来讲,数据源源不断地产生,形成一个无界的数据流(Unbounded Data Stream)。如 图 1.5 所示,单条数据被称为事件(Event),事件按照时序排列会形成一个数据流。例如,我们每时每刻的运动数据都会累积到手机传感器上,金融交易随时随地都在发生,物联网(Internet of Things,IoT)传感器会持续监控并生成数据。
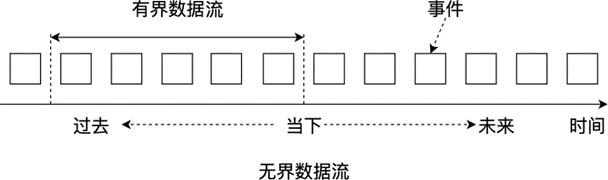
图 1.5 数据和数据流#
数据流中的某段有界数据流(Bounded Data Stream)可以组成一个数据集。我们通常所说的对某份数据进行分析,指的是对某个数据集进行分析。随着数据的产生速度越来越快,数据源越来越多,人们对时效性的重视程度越来越高,如何处理数据流成了大家更为关注的问题。
在本书以及其他官方资料中,也会将单条事件称为一条数据或一个元素(Element)。在本书后文的描述中,事件、数据、元素这 3 个概念均可以用来表示数据流中的某个元素。
批处理与流处理#
批处理#
批处理(Batch Processing)是指对一批数据进行处理。我们身边的批处理比比皆是,最常见的批处理例子有:微信运动每天晚上有一个批处理任务,把用户好友一天所走的步数统计一遍,生成排序结果后推送给用户;银行信用卡中心每月账单日有一个批处理任务,把一个月的消费总额统计一次,生成用户月度账单;国家统计局每季度对经济数据做一次统计,公布季度国内生产总值(GDP)。可见,批处理任务一般是对一段时间的数据聚合后进行处理的。对于数据量庞大的应用,如微信运动、银行信用卡中心等情景,一段时间内积累的数据总量非常大,计算非常耗时。
流处理#
如前文所述,数据其实是以流(Stream)的方式持续不断地产生着的,流处理(Stream Processing)就是对数据流进行处理。时间就是金钱,对数据流进行分析和处理,获取实时数据价值越发重要。如 “双十一电商大促销”,管理者要以秒级的响应时间查看实时销售业绩、库存信息以及与竞品的对比结果,以争取更多的决策时间;股票交易要以毫秒级的速度来对新信息做出响应;风险控制要对每一份欺诈交易迅速做出处理,以减少不必要的损失;网络运营商要以极快速度发现网络和数据中心的故障;等等。以上这些场景,一旦出现故障,造成服务的延迟,损失都难以估量。因此,响应速度越快,越能减少损失、增加收入。而 IoT 和 5G 的兴起将为数据生成提供更完美的底层技术基础,海量的数据在 IoT 设备上采集,并通过高速的 5G 通道传输到服务器,庞大的实时数据流将汹涌而至,流处理的需求肯定会爆炸式增长。
为什么需要一个优秀的流处理框架#
处理实时流的系统通常被称为流计算框架、实时计算框架或流处理框架。下面就来解释为何需要一个可靠的流处理框架。
股票交易的业务场景#
我们都知道股票交易非常依赖各类信息,一些有可能影响股票市场价格的信息经常首发于财经网站、微博、微信等社交媒体平台上。作为人类的我们不可能 24 小时一直监控各类媒体,如果有一个自动化的系统来做一些分析和预警,将为决策者争取到更多时间。
假设我们有数只股票的交易数据流,我们可以通过这个数据流来计算以 10 秒为一个时间窗口的股票价格波动,选出那些超过 5% 变化幅度的股票,并将这些股票与媒体的实时文本数据做相关分析,以判断媒体上的哪些实时信息会影响股票价格。当相关分析的结果足够有说服力时,可以将这个系统部署到生产环境,实时处理股票与媒体数据,产生分析报表,并发送给交易人员。那么,如何构建一个可靠的程序来解决上述业务场景问题呢?
生产者 - 消费者模型#
处理流数据一般使用 “生产者 - 消费者”(Producer-Consumer)模型来解决问题。如 图 1.6 所示,生产者生成数据,将数据发送到一个缓存区域(Buffer),消费者从缓存区域中消费数据。这里我们暂且不关心生产者如何生产数据,以及数据如何缓存,我们只关心如何实现消费者。
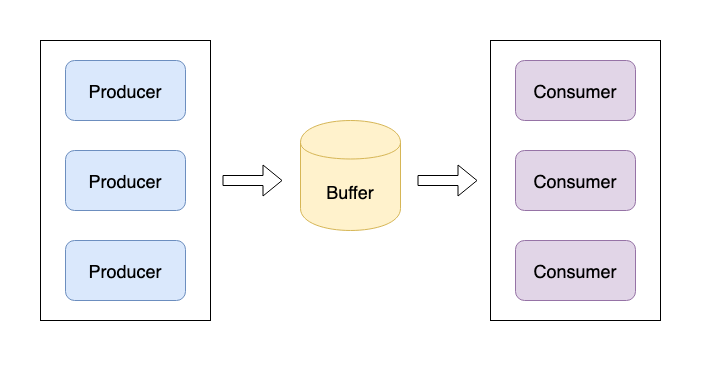
图 1.6 生产者 - 消费者模型#
在股票交易的场景中,我们可以启动一个进程来实现消费者,该进程以 10 秒为一个时间窗口,统计时间窗口内的交易情况,找到波动最大的那些股票。同时,该进程也对新流入的媒体文本进行分析。这个逻辑看起来很容易实现,但深挖之后会发现问题繁多。
流处理框架要解决的诸多问题#
可扩展性#
股票交易和媒体文本的数据量都非常大,仅以微博为例,平均每秒有上千条、每天有上亿条微博数据。一般情况下,单个节点无法处理这样规模的数据,这时候需要使用分布式计算。假如我们使用类似 MPI 的框架,需要手动设计分治算法,这对很多程序员来说有一定的挑战性。
随着数据不断增多,我们能否保证我们的程序能够快速扩展到更多的节点上,以应对更多的计算需求?具体而言,当计算需求增多时,计算资源能否线性增加而不是耗费大量的资源,程序的代码逻辑能否保持简单而不会变得极其复杂?一个具有可扩展性的系统必须能够优雅地解决这些问题。
数据倾斜#
在分布式计算中,数据需要按照某种规则分布到各个节点上。假如数据路由规则设计得不够完善,当数据本身分布不均匀时,会发生数据倾斜,这很可能导致部分节点数据量远大于其他节点。这样的后果是:轻则负载重的节点延迟过高,重则引发整个系统的崩溃。假如一条突发新闻在网络媒体平台引发激烈的讨论和分析,数据突增,程序很可能会崩溃。数据倾斜是分布式计算中经常面临的一个问题。
容错性#
整个系统崩溃重启后,之前的那些计算如何恢复?或者部分节点发生故障,如何将该节点上的计算迁移到其他的节点上?我们需要一个机制来做故障恢复,以增强系统的容错性。
时序错乱#
限于网络条件和其他各种潜在影响因素,流处理引擎处理某个事件的时间并不是事件本来发生的时间。比如,你想统计上午 11:00:00 到 11:00:10 的交易情况,然而发生在 11:00:05 的某项交易因网络延迟没能抵达,这时候要直接放弃这项交易吗?绝大多数情况下我们会让程序等待,比如我们会假设数据最晚不会延迟超过 10 分钟,因此程序会等待 10 分钟。等待一次也还能接受,但是如果有多个节点在并行处理呢?每个节点等待一段时间,最后做数据聚合时就要等待更长时间。
批处理框架一般处理一个较长时间段内的数据,数据的时序性对其影响较小。批处理框架用更长的时间来换取更好的准确性。流处理框架对时序错乱更为敏感,框架的复杂程度也因此大大增加。
Flink 是解决上述问题的最佳选择之一。如果用 Flink 去解决前文提到的股票建模问题,只需要设置时间窗口,并在这个时间窗口下做一些数据处理的操作,还可以根据数据量来设置由多少节点并行处理。