8.4. Join#
Note
本教程已出版为《Flink 原理与实践》,感兴趣的读者请在各大电商平台购买!
Join 是 SQL 中最常用的数据处理机制,它可以将两个数据源中的相关行相互连接起来。常用的 Join 方式有:INNER JOIN、LEFT/RIGHT/FULL OUTER JOIN。不同的 Join 决定了两个数据源连接方式的不同。在批处理上,对静态的数据上进行 Join 已经比较成熟,常用的算法有:嵌套循环(Nested Join)、排序合并(Sort Merge)、哈希合并(Hash Merge)等。这里以嵌套循环为例解释一下 Join 的实现原理。
假设我们有这样一个批处理查询:
SELECT
orders.order_id,
customers.customer_name,
orders.order_date
FROM orders INNER JOIN customers
ON orders.customer_id = customers.customer_id;
这个语句在两个确定的数据集上进行计算,它翻译成伪代码:
// 循环遍历 orders 的每个元素
for row_order in orders:
// 循环遍历 customers 的每个元素
for row_customer in customers:
if row_order.customer_id = row_customer.customer_id
return (row_order.order_id, row_customer.customer_mame, row_order.order_date)
end
end
嵌套循环的基本原理是使用两层循环,遍历表中的每个元素,当两个表中的数据相匹配时,返回结果。我们知道,一旦数据量增大,嵌套循环算法会产生非常大的计算压力。之前多次提到,流处理场景下数据是不断生成的,一旦数据源有更新,相应的 Dynamic Table 也要随之更新,进而重新进行一次上述的循环算法,这对流处理来说是一个不小的挑战。
目前,Flink 提供了三种基于 Dynamic Table 的 Join:时间窗口 Join(Time-windowed Join)、临时表 Join(Temporal Table Join)和传统意义上的 Join(Regular Join)。这里我们先介绍前两种流处理中所特有的 Join,了解前两种流处理的特例可以让我们更好地理解传统意义上的 Join。
Time-windowed Join#
在电商平台,我们作为客户一般会先和卖家聊天沟通,经过一些对话之后才会下单购买。这里我们做一个简单的数据模型,假设一个关于聊天对话的数据流 chat 表记录了买家首次和卖家的聊天信息,它包括以下字段:买家 ID(buyer_id),商品 ID(item_id),时间戳(ts)。如果买家从开启聊天到最后下单的速度比较快,说明这个商品的转化率比较高,非常值得进一步分析。我们想统计这些具有较高转化率的商品,比如统计从首次聊天到用户下单购买的时间小于 1 分钟。

图 8.12 Time-windowed Join:聊天对话和用户行为的 Join#
图 8.12 中,左侧为记录用户首次聊天的数据流 chat 表,它有两个字段:buyer_id、item_id 和 ts, 右侧为我们之前一直使用的 user_behavior。我们以 item_id 字段来对两个数据流进行 Join,同时还增加一个时间窗口的限制,即首次聊天发生之后 1 分钟内用户有购买行为。相应的 SQL 语句如下:
SELECT
user_behavior.item_id,
user_behavior.ts AS buy_ts
FROM chat, user_behavior
WHERE chat.item_id = user_behavior.item_id
AND user_behavior.behavior = 'buy'
AND user_behavior.ts BETWEEN chat.ts AND chat.ts + INTERVAL '1' MINUTE;
Time-windowed Join 其实和第五章中的 Interval Join 比较相似,可以用 图 8.13 来解释其原理。我们对 A 和 B 两个表做 Join,需要对 B 设置一个上下限,A 表中所有界限内的数据都要与 B 表中的数据做连接。
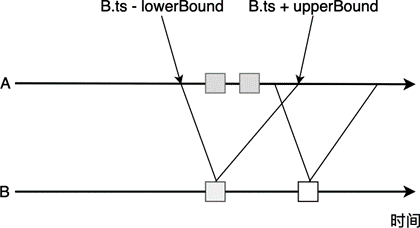
图 8.13 Time-windowed Join 时间线#
一个更加通用的模板为:
SELECT
*
FROM A, B
WHERE A.id = B.id
AND A.ts BETWEEN B.ts - lowBound AND B.ts + upperBound;
从语法中可以读出,BETWEEN ... AND ... 设置了一个时间窗口,B 表中某个元素的窗口为:[B.ts - lowBound, B.ts + upperBound] 的闭区间,如果 A 表元素恰好落在这个区间,则该元素与 B 中这个元素连接。其中,A 和 B 都使用时间属性进行上述窗口操作。此外,我们还需要等于谓词来进行匹配,比如 A.id = B.id,否则大量数据会被连接到一起。
除了使用 BETWEEN ... AND ... 来确定窗口起始结束点外,Flink 也支持比较符号 >, <, >=, <=,所以,一个时间窗口也可以被写为 A.ts >= B.ts - lowBound AND A.ts <= B.ts + upperBound 这样的语法。
A 表和 B 表必须是 Append-only 模式的表,即只可以追加,不可以更新。
在实现上,Flink 使用状态来存储一些时间窗口相关数据。时间一般接近单调递增(Event Time 模式不可能保证百分百的单调递增)。过期后,这些状态数据会被清除。当然,使用 Event Time 意味着窗口要等待更长的时间才能关闭,状态数据会更大。
Temporal Table Join#
电商平台的商品价格有可能发生变化,假如我们有一个商品数据源,里面有各个商品的价格变动,它由 item_id、price 和 version_ts 组成,其中,price 为当前的价格,version_ts 为价格改动的时间戳。一旦一件商品的价格有改动,数据都会追加到这个表中,这个表保存了价格变动的日志。如果我们想获取一件被购买的商品最近的价格,需要从这个表中找到最新的数据。这个表可以根据时间戳拆分为临时表(Temporal Table),Temporal Table 如 图 8.14 所示:
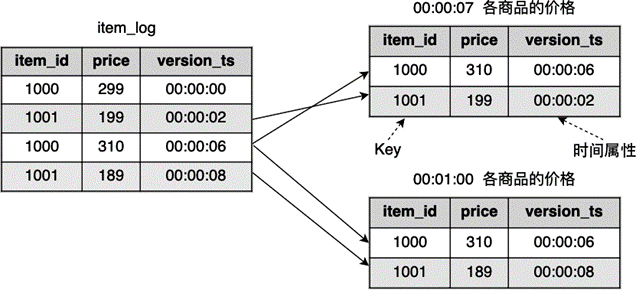
图 8.14 将 item_log 拆解为临时表#
从 图 8.14 可以看到,由于商品价格在更新,不同时间点的各商品价格不同。假如我们想获取 00:00:07 时刻各商品价格,得到的结果为右侧上表,如果获取 00:01:00 时刻各商品的价格,得到的结果为右侧下表。从图中拆解的过程可以看到,Temporal Table 可以让我们获得某个时间点的信息,就像整个数据的一个子版本,版本之间通过时间属性来区分。
对于 Temporal Table 来说,数据源必须是一个 Append-only 的追加表,表中有一个 Key 作为唯一标识,数据追加到这个表后,我们可以根据 Key 来更新 Temporal Table。上图中的表使用 item_id 作为 Key。每行数据都有一个时间属性,用来标记不同的版本,时间属性可以是 Event Time 也可以是 Processing Time。上图中的表使用 version_ts 作为时间属性字段。
总结下来,定义一个 Temporal Time 需要注意以下几点:
数据源是一个 Append-only 的追加表
定义 Key,Key 用来做唯一标识
数据源中有时间属性字段,根据时间的先后来区分不同的版本
下面的代码生成 Temporal Table,其中 registerFunction 方法对这个 Temporal Table 进行了注册,它定义了 Key 并指定了时间属性字段,我们将在用户自定义方法的章节中专门介绍 registerFunction 使用方法。
DataStream<Tuple3<Long, Long, Timestamp>> itemStream = ...
// 获取 Table
Table itemTable = tEnv.fromDataStream(itemStream, "item_id, price, version_ts.rowtime");
// 注册 Temporal Table Function,指定时间属性和 Key
tEnv.registerFunction("item", itemTable.createTemporalTableFunction("version_ts", "item_id"));
注册后,我们拥有了一个名为 item 的 Temporal Table,接下来可以在 SQL 中对这个表进行 Join:
SELECT
user_behavior.item_id,
latest_item.price,
user_behavior.ts
FROM
user_behavior, LATERAL TABLE(item(user_behavior.ts)) AS latest_item
WHERE user_behavior.item_id = latest_item.item_id
AND user_behavior.behavior = 'buy'
这个 SQL 语句筛选购买行为:user_behavior.behavior = 'buy',Temporal Table item(user_behavior.ts) 按照 user_behavior 表中的时间 ts 来获取该时间点上对应的 item 的版本,将这个表重命名为 latest_item。这个 SQL 语句的计算过程如 图 8.15 所示:
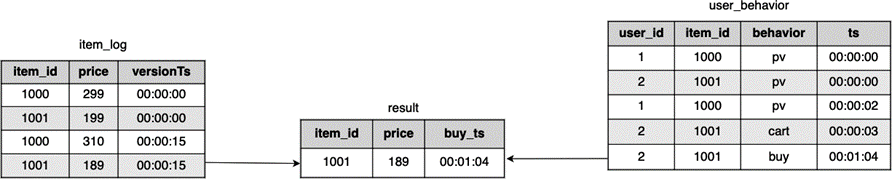
图 8.15 Temporal Table Join:对 user_behavior 和 item_log 进行 Join#
整个程序的 Java 实现如下:
// userBehavior
DataStream<Tuple4<Long, Long, String, Timestamp>> userBehaviorStream = env
.fromCollection(userBehaviorData)
// 使用 Event Time 必须设置时间戳和 Watermark
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple4<Long, Long, String, Timestamp>>() {
@Override
public long extractAscendingTimestamp(Tuple4<Long, Long, String, Timestamp> element) {
return element.f3.getTime();
}
});
// 获取 Table
Table userBehaviorTable = tEnv.fromDataStream(userBehaviorStream, "user_id, item_id, behavior,ts.rowtime");
tEnv.createTemporaryView("user_behavior", userBehaviorTable);
// item
DataStream<Tuple3<Long, Long, Timestamp>> itemStream = env
.fromCollection(itemData)
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<Long, Long, Timestamp>>() {
@Override
public long extractAscendingTimestamp(Tuple3<Long, Long, Timestamp> element) {
return element.f2.getTime();
}
});
Table itemTable = tEnv.fromDataStream(itemStream, "item_id, price, version_ts.rowtime");
// 注册 Temporal Table Function,指定时间戳和 Key
tEnv.registerFunction(
"item",
itemTable.createTemporalTableFunction("version_ts", "item_id"));
String sqlQuery = "SELECT \n" +
" user_behavior.item_id," +
" latest_item.price,\n" +
" user_behavior.ts\n" +
"FROM " +
" user_behavior, LATERAL TABLE(item(user_behavior.ts)) AS latest_item\n" +
"WHERE user_behavior.item_id = latest_item.item_id" +
" AND user_behavior.behavior = 'buy'";
// 执行 SQL 语句
Table joinResult = tEnv.sqlQuery(sqlQuery);
DataStream<Row> result = tEnv.toAppendStream(joinResult, Row.class);
从时间维度上来看,Temporal Table Join 的效果如 图 8.16 所示。
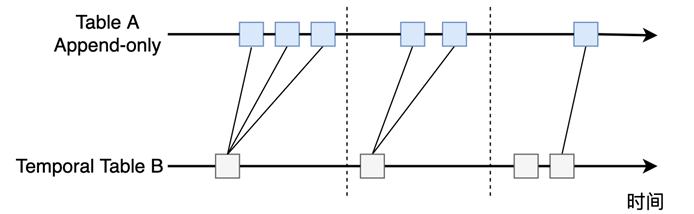
图 8.16 Append-only Table 与 Temporal Table 进行 Join 操作#
将这个场景推广,如果想在其他地方使用 Temporal Table Join,需要按照下面的模板编写 SQL:
SELECT *
FROM A, LATERAL TABLE(B(A.ts))
WHERE A.id = B.id
使用时,要注意:
A 表必须是一个 Append-only 的追加表。
B 表的数据源必须是一个 Append-only 的追加表,且必须使用
registerFunction将该表注册到 Catalog 中。注册时需要指定 Key 和时间属性。A 表和 B 表通过 Key 进行等于谓词匹配:
A.id = B.id。
在具体实现 Temporal Table 时,Flink 维护了一个类似 Keyed State 的状态,某个 Key 值下会保存对应的数据。Event Time 下,为了等待一些迟到数据,状态数据会更大一些。
Regular Join#
基于前面列举的两种时间维度上的 Join,我们可以更好地理解传统意义上的 Regular Join。对于刚刚的例子,如果商品表不是把所有改动历史都记录下来,而是只保存了某一时刻的最新值,那么我们应该使用 Regular Join。如下图所示,item 表用来存储当前最新的商品信息数据,00:02:00 时刻,item 表有了改动,Join 结果如 图 8.17 中的 result 表。
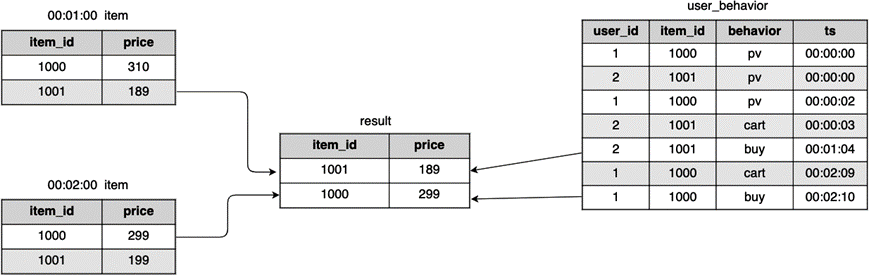
图 8.17 Regular Join#
实际上,大部分数据库都如 图 8.17 中左侧所示,只保存数据的最新值,而数据库的改动历史日志不会呈现给用户,仅用来做故障恢复。那么,对于这种类型的表,具体的 SQL 语句为:
SELECT
user_behavior.item_id,
item.price
FROM
user_behavior, item
WHERE user_behavior.item_id = item.item_id
AND user_behavior.behavior = 'buy'
Regular Join 是最常规的 Join,它不像 Time-windowed Join 和 Temporal Table Join 那样需要在 SQL 语句中考虑太多时间。它的 SQL 语法也和批处理中的 Join 一样,一般符合下面的模板:
SELECT *
FROM A INNER JOIN B
ON A.id = B.id
A 和 B 可以是 Append-only 的追加表,也可以是可更新的 Update 表,A、B 两个表中的数据可以插入、删除和更新。A、B 表对应的元素都会被连接起来。在具体实现上,Flink 需要将两个表都放在状态中存储。任何一个表有新数据加入,都会和另外表中所有对应行进行连接。因此,Regular Join 适合输入源不太大或源数据增长量非常小的场景。我们可以配置一定的过期时间,超过这个时间后,数据会被清除。我们在 Dynamic Table 节提到的使用下面的方法来设置过期时间:tEnv.getConfig.setIdleStateRetentionTime(Time.hours(1), Time.hours(2))。
目前,Flink 可以支持 INNER JOIN、LEFT JOIN、RIGHT JOIN 和 FULL OUTER JOIN,只支持等于谓词匹配:ON A.id = B.id。使用 Regular Join 时,尽量避免出现笛卡尔积式的连接。
在 Regular Join 中,我们无法 SELECT 时间属性,因为 Flink SQL 无法严格保证数据按照时间属性排序。如果我们想要 SELECT 时间字段,一个办法是在定义 Schema 时,不明确指定该字段为时间属性,比如使用 SQL DDL 定义时,不设置 WATERMARK FOR rowtime_column AS watermark_strategy_expression。