7.2. 自定义 Source 和 Sink#
本节将从原理和实现两个方面来介绍 Flink 的 Source 和 Sink。
Flink 1.11 之前的 Source#
Flink 1.11 重构了 Source 接口,是一个非常大的改动,新的 Source 接口提出了一些新的概念,在使用方式上与老 Source 接口有较大区别。这里将先重点介绍老的 Source 接口,因为老的 Source 接口更易于理解和实现,之后会简单介绍新的 Source 接口的原理。
实现 SourceFunction#
在本书提供的示例程序中曾大量使用各类自定义的 Source,Flink 提供了自定义 Source 的公开接口:SourceFunction 的接口和 RichSourceFunction 的 Rich 函数类。自定义 Source 时必须实现两个方法。
// Source 启动后调用 run() 方法,生成数据并将其向下游发送
void run(SourceContext<T> ctx) throws Exception;
// 停止
void cancel();
run()方法在 Source 启动后开始执行,一般都会在方法中使用循环,在循环内不断向下游发送数据,发送数据时使用 SourceContext.collect() 方法。cancel()方法停止向下游继续发送数据。由于 run() 方法内一般会使用循环,可以使用一个 boolean 类型的标志位来标记 Source 是否在执行。当停止 Source 时,也要修改这个标志位。代码清单 7-1 自定义 Source,从 0 开始计数,将数字发送到下游。
private static class SimpleSource
implements SourceFunction<Tuple2<String, Integer>> {
private int offset = 0;
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
while (isRunning) {
Thread.sleep(500);
ctx.collect(new Tuple2<>("" + offset, offset));
offset++;
if (offset == 1000) {
isRunning = false;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
}
在主逻辑中调用这个 Source。
DataStream<Tuple2<String, Integer>> countStream = env.addSource(new SimpleSource());
与第 4 章中介绍的 DataStream API 类似,RichSourceFunction 提供了 RuntimeContext,以及增加了 open()方法用来初始化资源,close() 方法用来关闭资源。RuntimeContext 指运行时上下文,包括并行度、监控项 MetricGroup 等。比如,我们可以使用 getRuntimeContext().getIndexOfThisSubtask() 获取当前子任务是多个并行子任务中的哪一个。
可恢复的 Source#
对于代码清单 7-1 所示的示例中,假如遇到故障,整个作业重启,Source 每次从 0 开始,没有记录遇到故障前的任何信息,所以它不是一个可恢复的 Source。我们在 7.1 节中讨论过,Source 需要支持数据重发才能支持端到端的 Exactly-Once 保障。如果想支持数据重发,需要满足如下两点。
Flink 开启 Checkpoint 机制,Source 将数据 Offset 定期写到 Checkpoint 中。作业重启后,Flink Source 从最近一次的 Checkpoint 中恢复 Offset 数据。
Flink 所连接的上游系统支持从某个 Offset 开始重发数据。如果上游是 Kafka,它是支持 Offset 重发的。如果上游是一个文件系统,读取文件时可以直接跳到 Offset 所在的位置,从该位置重新读取数据。
在第 6 章中我们曾详细讨论 Flink 的 Checkpoint 机制,其中提到 Operator State 经常用来在 Source 或 Sink 中记录 Offset。我们在代码清单 7-1 的基础上做了一些修改,让整个 Source 能够支持 Checkpoint,即使遇到故障,也可以根据最近一次 Checkpoint 中的数据进行恢复,如代码清单 7-2 所示。
private static class CheckpointedSource
extends RichSourceFunction<Tuple2<String, Integer>>
implements CheckpointedFunction {
private int offset;
private boolean isRunning = true;
private ListState<Integer> offsetState;
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
while (isRunning) {
Thread.sleep(100);
// 使用同步锁,当触发某次 Checkpoint 时,不向下游发送数据
synchronized (ctx.getCheckpointLock()) {
ctx.collect(new Tuple2<>("" + offset, 1));
offset++;
}
if (offset == 1000) {
isRunning = false;
}
}
}
@Override
public void cancel() {
isRunning = false;
}
@Override
public void snapshotState(FunctionSnapshotContext snapshotContext) throws
Exception {
// 清除上次状态
offsetState.clear();
// 将最新的 Offset 添加到状态中
offsetState.add(offset);
}
@Override
public void initializeState(FunctionInitializationContext initializationContext) throws Exception {
// 初始化 offsetState
ListStateDescriptor<Integer> desc = new
ListStateDescriptor<Integer>("offset", Types.INT);
offsetState =
initializationContext.getOperatorStateStore().getListState(desc);
Iterable<Integer> iter = offsetState.get();
if (iter == null || !iter.iterator().hasNext()) {
// 第一次初始化,从 0 开始计数
offset = 0;
} else {
// 从状态中恢复 Offset
offset = iter.iterator().next();
}
}
}
代码清单 7-2 继承并实现了 CheckpointedFunction,可以使用 Operator State。整个作业第一次执行时,Flink 会调用 initializeState()方法,offset 被设置为 0,之后每隔一定时间触发一次 Checkpoint,触发 Checkpoint 时会调用 snapshotState() 方法来更新状态到 State Backend。如果遇到故障,重启后会从 offsetState 状态中恢复上次保存的 Offset。
在 run()方法中,我们增加了一个同步锁 ctx.getCheckpointLock(),是为了当触发这次 Checkpoint 时,不向下游发送数据。或者说,等本次 Checkpoint 触发结束,snapshotState()方法执行完,再继续向下游发送数据。如果没有这个步骤,有可能会导致 run() 方法中 Offset 和 snapshotState() 方法中 Checkpoint 的 Offset 不一致。
需要注意的是,主逻辑中需要开启 Checkpoint 机制,如代码清单 7-3 所示。
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 访问 http://localhost:8082 可以看到 Flink WebUI
conf.setInteger(RestOptions.PORT, 8082);
// 设置本地执行环境,并行度为 1
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironment(1, conf);
// 每隔 2 秒触发一次 Checkpoint
env.getCheckpointConfig().setCheckpointInterval(2 * 1000);
DataStream<Tuple2<String, Integer>> countStream = env.addSource(new
CheckpointedSource());
// 每隔一定时间模拟一次故障
DataStream<Tuple2<String, Integer>> result = countStream.map(new
FailingMapper(20));
result.print();
env.execute("checkpointed source");
}
上述代码使用 FailingMapper 模拟了一次故障。即使发生了故障,Flink 仍然能自动重启,并从最近一次的 Checkpoint 数据中恢复状态。
时间戳和 Watermark#
在 5.1.3 小节,我们曾经介绍过如何设置一个基于 Event Time 数据流的时间戳和 Watermark,其中一种办法就是在 Source 中设置。在自定义 Source 的过程中,SourceFunction.SourceContext 提供了相应的方法。
// 设置 element 的时间戳为 timestamp,并将 element 发送出去
void collectWithTimestamp(T element, long timestamp);
// 发送一个 Watermark
void emitWatermark(Watermark mark);
其中,SourceContext.collectWithTimestamp()是一种针对 Event Time 的发送数据的方法,它是 SourceContext.collect() 的一种特例。比如,我们可以将计数器 Source 中的 run() 方法修改如下。
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
while (isRunning) {
Thread.sleep(100);
// 将系统当前时间作为该数据的时间戳,并发送出去
ctx.collectWithTimestamp(new Tuple2<>("" + offset, offset),
System.currentTimeMillis());
offset++;
// 每隔一段时间,发送一个 Watermark
if (offset % 100 == 0) {
ctx.emitWatermark(new Watermark(System.currentTimeMillis()));
}
if (offset == 1000) {
isRunning = false;
}
}
}
如果使用 Event Time 时间语义,越早设置时间戳和 Watermark,越能保证整个作业在时间序列上的准确性和健壮性。
我们在 5.1.3 小节也曾介绍过,对于 Event Time 时间语义,算子有一个 Watermark 对齐的过程,某些上游数据源没有数据,将导致下游算子一直等待,无法继续处理新数据。这时候要及时使用 SourceContext.markAsTemporarilyIdle() 方法将该 Source 标记为空闲。比如,在实现 Flink Kafka Source 时,源码如下。
public void run(SourceContext<T> sourceContext) throws Exception {
...
// 如果当前 Source 没有数据,将当前 Source 标记为空闲
// 如果当前 Source 发现有新数据流入,会自动回归活跃状态
if (subscribedPartitionsToStartOffsets.isEmpty()) {
sourceContext.markAsTemporarilyIdle();
}
...
}
并行版本#
上面提到的 Source 都是并行度为 1 的版本,或者说启动后只有一个子任务在执行。如果需要在多个子任务上并行执行的 Source,可以实现 ParallelSourceFunction 和 RichParallelSourceFunction 两个类。
7.2.2 Flink 1.11 之后的 Source#
仔细分析上面的 Source 接口,可以发现这样的设计只适合进行流处理,批处理需要另外的接口。Flink 在 1.11 之后提出了一个新的 Source 接口,主要目的是统一流处理和批处理两大计算模式,提供更大规模并行处理的能力。新的 Source 接口仍然处于实验阶段,一些 Connnector 仍然基于老的 Source 接口来实现的,本书只介绍大概的原理,暂时不从代码层面做具体展示。相信在不久的未来,更多 Connector 将使用新的 Source 接口来实现。
新的 Source 接口提出了 3 个重要组件。
** 分片(Split)**:Split 是将数据源切分后的一小部分。如果数据源是文件系统上的一个文件夹,Split 可以是文件夹里的某个文件;如果数据源是一个 Kafka 数据流,Split 可以是一个 Kafka Partition。因为对数据源做了切分,Source 就可以启动多个实例并行地读取。
** 读取器(SourceReader)**:SourceReader 负责 Split 的读取和处理,SourceReader 运行在 TaskManager 上,可以分布式地并行运行。比如,某个 SourceReader 可以读取文件夹里的单个文件,多个 SourceReader 实例共同完成读取整个文件夹的任务。
** 分片枚举器 (SplitEnumerator)**:SplitEnumerator 负责发现和分配 Split。SplitEnumerator 运行在 JobManager 上,它会读取数据源的元数据并构建 Split,然后按照负载均衡策略将多个 Split 分配给多个 SourceReader。
图 7.3 展示了这 3 个组件之间的关系。其中,Master 进程中的 JobManager 运行着 SplitEnumerator,各个 TaskManager 中运行着 SourceReader,SourceReader 每次向 SplitEnumerator 请求 Split,SplitEnumerator 会分配 Split 给各个 SourceReader。
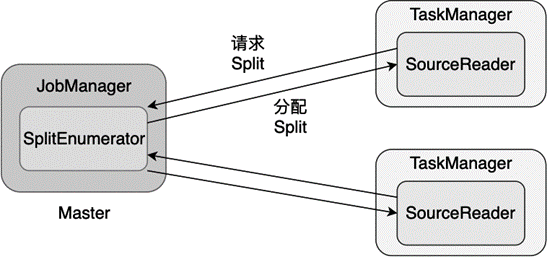
图 7.3 新 Source 接口中的 3 个重要组件#
自定义 Sink#
对于 Sink,Flink 提供的 API 为 SinkFunction 接口和 RichSinkFunction 函数类。使用时需要实现下面的虚方法。
// 每条数据到达 Sink 后都会调用 invoke() 方法,发送到下游外部系统
// value 为待输出数据
void invoke(IN value, Context context)
如 7.1 节所讨论的问题,如果想提供端到端的 Exactly-Once 保障,需要使用幂等写和事务写两种方式。
幂等写#
幂等写需要综合考虑业务系统的设计和下游外部系统的选型等多方面因素。数据流的一条数据经过 Flink 可能产生一到多次计算(因为故障恢复),但是最终输出的结果必须是可确定的,不能因为多次计算,导致一些变化。比如我们在前文中提到的,结果中使用系统当前时间戳作为 Key 就不是一个可确定的计算,因为每次计算的结果会随着系统当前时间戳发生变化。另外,写入外部系统一般是采用更新插入(Upsert)的方式,即将原有数据删除,将新数据插入,或者说将原有数据覆盖。一些 Key-Value 数据库经常被用来实现幂等写,幂等写也是一种实现成本相对比较低的方式。
事务写#
另外一种提供端到端 Exactly-Once 保障的方式是事务写,并且有两种具体的实现方式:Write-Ahead-Log 和 Two-Phase-Commit。两者非常相似,下面分别介绍两种方式的原理,并重点介绍 Two-Phase-Commit 的具体实现。
Write-Ahead-Log 协议的原理#
Write-Ahead-Log 是一种广泛应用在数据库和分布式系统中的保证事务一致性的协议。Write-Ahead-Log 的核心思想是,在数据写入下游系统之前,先把数据以日志(Log)的形式缓存下来,等收到明确的确认提交信息后,再将 Log 中的数据提交到下游系统。由于数据都写到了 Log 里,即使出现故障恢复,也可以根据 Log 中的数据决定是否需要恢复、如何进行恢复。图 7.4 所示为 Flink 的 Write-Ahead-Log 流程。
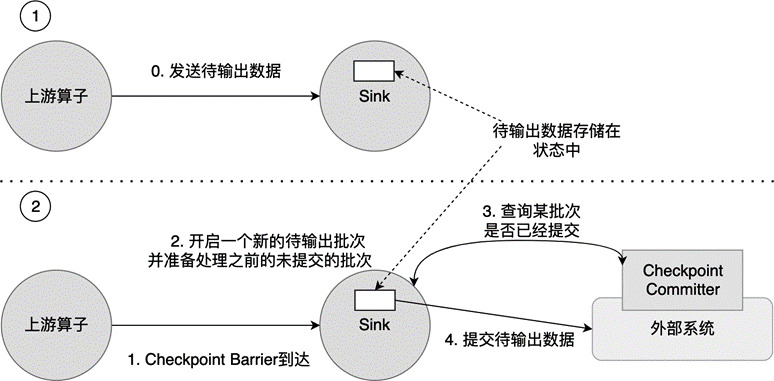
图 7.4 Flink 的 Write-Ahead-Log 流程#
在 Flink 中,上游算子会不断向 Sink 发送待输出数据,这些待输出数据暂时存储在状态中,如 图 7.4 的第 0 步所示。两次 Checkpoint 之间的待输出数据组成一个待输出的批次,会以 Operator State 的形式保存和备份。当 Sink 接收到一个新 Checkpoint Barrier 时,意味着 Sink 需要执行新一次 Checkpoint,它会开启一个新的批次,新流入数据都进入该批次。同时,Sink 准备将之前未提交的批次提交给外部系统。图 7.4 所示的第 1 步和第 2 步展示了这个过程。数据提交的过程又分为如下 3 步。
Sink 向 CheckpointCommitter 查询某批次是否已经提交,通常 CheckpointCommitter 是一个与外部系统紧密相连的插件,里面存储了各批次数据是否已经写入外部系统的信息。比如,Cassandra 的 CassandraCommitter 使用了一个单独的表存储某批次数据是否已经提交。如果还未提交,则返回 false。如果外部系统是一个文件系统,我们用一个文件存储哪些批次数据已经提交。总之,CheckpointCommitter 依赖外部系统,它依靠外部系统存储了是否提交的信息。这个过程如 图 7.4 的第 3 步所示。
Sink 得知某批次数据还未提交,则使用 sendValues()方法,提交待输出数据到外部系统,即 图 7.4 的第 4 步。此时,数据写入外部系统,同时也要在 CheckpointCommitter 中更新本批次数据已被提交的确认信息。
数据提交成功后,Sink 会删除 Operator State 中存储的已经提交的数据。
Write-Ahead-Log 仍然无法提供百分之百的 Exactly-Once 保障,原因如下。
sendValues() 中途可能崩溃,导致部分数据已提交,部分数据还未提交。
sendValues() 成功,但是本批次数据提交的确认信息未能更新到 CheckpointCommitter 中。
这两种原因会导致故障恢复后,某些数据可能会被多次写入外部系统。
Write-Ahead-Log 的方式相对比较通用,目前 Flink 的 Cassandra Sink 使用这种方式提供 Exactly-Once 保障。
Two-Phase-Commit 协议的原理和实现#
Two-Phase-Commit 是另一种广泛应用在数据库和分布式系统中的事务协议。与刚刚介绍的 Write-Ahead-Log 相比,Flink 中的 Two-Phase-Commit 协议不将数据缓存在 Operator State,而是将数据直接写入外部系统,比如支持事务的 Kafka。图 7-4 为 Flink 的 Two-Phase-Commit 流程图。
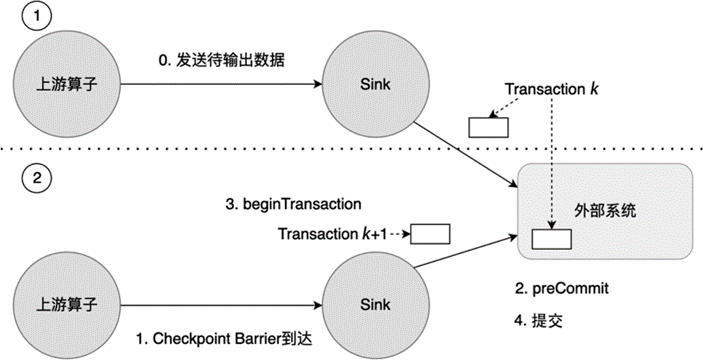
图 7.5 Flink 的 Two-Phase-Commit 流程图#
如 图 7.5 所示,上游算子将数据发送到 Sink 后,Sink 直接将待输出数据写入外部系统的第 k 次事务(Transaction)中。接着 Checkpoint Barrier 到达,新一次 Checkpoint 开始执行。如图 7-5 的第 2 步所示,Flink 执行 preCommit(),将第 k 次 Transaction 的数据预提交到外部系统中,预提交时,待提交数据已经写入外部系统,但是为了保证数据一致性,这些数据由于还没有得到确认提交的信息,对于外部系统的使用者来说,还是不可见的。之所以使用预提交而非提交,是因为 Flink 无法确定多个并行实例是否都完成了数据写入外部系统的过程,有些实例已经将数据写入,其他实例未将数据写入。一旦发生故障恢复,写入实例的那些数据还有可能再次被写入外部系统,这就影响了 Exactly-Once 保障的数据一致性。
接着,Flink 会执行 beginTransaction() 方法,开启下一次 Transaction(Transaction k+1),之后上游算子流入的待输出数据都将流入新的 Transaction,如图 7-5 的第 3 步。当所有并行实例都执行图 7-5 中的第 2 步和第 3 步之后,本次 Checkpoint 已经完成,Flink 将预提交的数据最终提交到外部系统,至此待输出数据在外部系统最终可见。
接下来我们使用具体的例子来演示整个数据写入的过程,这里继续使用本章之前一直使用的数据流 DataStream<Tuple2<String, Integer>>,我们将这个数据流写入文件。为此,我们准备两个文件夹,一个名为 flink-sink-commited,这是数据最终要写入的文件夹,需要保证一条数据从 Source 到 Sink 的 Exactly-Once 一致性;第二个文件夹名为 flink-sink-precommit,存储临时文件,主要为事务机制所使用。数据先经过 flink-sink-precommit,等得到确认后,再将数据从此文件夹写入 flink-sink-commited。结合上面所述的数据写入过程,我们需要继承 TwoPhaseCommitSinkFunction,并实现下面的 4 个方法。
beginTransaction():开启一次新的 Transaction。我们为每次 Transaction 创建一个新的文件缓存,文件缓存名以当前时间命名,新流入数据都写入这个文件缓存。假设当前为第 k 次 Transaction,文件名为 k。文件缓存的数据在内存中,还未写入磁盘。
preCommit():数据预提交。文件缓存 k 从内存写入 flink-sink-precommit 文件夹,数据持久化到磁盘中。一旦 preCommit() 方法被执行,Flink 会调用 beginTransaction() 方法,开启下一次 Transaction,生成名为 k+1 的文件缓存。
commit():得到确认后,提交数据。将文件 k 从 flink-sink-precommit 文件夹移动到 flink-sink-commited。
abort():遇到异常,操作终止。将 flink-sink-precommit 中的文件删除。
除此之外,还需要实现 Sink 最基本的数据写入方法 invoke(),将数据写入文件缓存。代码清单 7-4 展示了整个过程。
public static class TwoPhaseFileSink
extends TwoPhaseCommitSinkFunction<Tuple2<String, Integer>, String, Void> {
// 缓存
private BufferedWriter transactionWriter;
private String preCommitPath;
private String commitedPath;
public TwoPhaseFileSink(String preCommitPath, String commitedPath) {
super(StringSerializer.INSTANCE, VoidSerializer.INSTANCE);
this.preCommitPath = preCommitPath;
this.commitedPath = commitedPath;
}
@Override
public void invoke(String transaction, Tuple2<String, Integer> in, Context context) throws Exception {
transactionWriter.write(in.f0 + " " + in.f1 + "\n");
}
@Override
public String beginTransaction() throws Exception {
String time =
LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_DATE_TIME);
int subTaskIdx = getRuntimeContext().getIndexOfThisSubtask();
String fileName = time + "-" + subTaskIdx;
Path preCommitFilePath = Paths.get(preCommitPath + "/" + fileName);
// 创建一个存储本次 Transaction 的文件
Files.createFile(preCommitFilePath);
transactionWriter = Files.newBufferedWriter(preCommitFilePath);
System.out.println("transaction File: " + preCommitFilePath);
return fileName;
}
@Override
public void preCommit(String transaction) throws Exception {
// 将当前数据由内存写入磁盘
transactionWriter.flush();
transactionWriter.close();
}
@Override
public void commit(String transaction) {
Path preCommitFilePath = Paths.get(preCommitPath + "/" + transaction);
if (Files.exists(preCommitFilePath)) {
Path commitedFilePath = Paths.get(commitedPath + "/" + transaction);
try {
Files.move(preCommitFilePath, commitedFilePath);
} catch (Exception e) {
System.out.println(e);
}
}
}
@Override
public void abort(String transaction) {
Path preCommitFilePath = Paths.get(preCommitPath + "/" + transaction);
// 如果中途遇到异常,将文件删除
if (Files.exists(preCommitFilePath)) {
try {
Files.delete(preCommitFilePath);
} catch (Exception e) {
System.out.println(e);
}
}
}
}
代码清单 7-4 实现了 TwoPhaseCommitSinkFunction 的 Sink
TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT> 接收如下 3 个泛型。
IN 为上游算子发送过来的待输出数据类型。
TXN 为 Transaction 类型,本例中是类型 String,Kafka 中是一个封装了 Kafka Producer 的数据类型,我们可以往 Transaction 中写入待输出的数据。
CONTEXT 为上下文类型,是个可选选项。本例中我们没有使用上下文,所以这里使用了 Void,即空类型。 TwoPhaseCommitSinkFunction 的构造函数需要传入 TXN 和 CONTEXT 的序列化器。在主逻辑中,我们创建了两个目录,一个为预提交目录,一个为最终的提交目录。我们可以比较使用未加任何保护的 print()和该 Sink:print() 直接将结果输出到标准输出,会有数据重发现象;而使用了 Two-Phase-Commit 协议,待输出结果写到了目标文件夹内,即使发生了故障恢复,也不会有数据重发现象,代码清单 7-5 展示了在主逻辑中使用 Two-Phase-Commit 的 Sink。
// 每隔 5 秒进行一次 Checkpoint
env.getCheckpointConfig().setCheckpointInterval(5 * 1000);
DataStream<Tuple2<String, Integer>> countStream = env.addSource(new
CheckpointedSourceExample.CheckpointedSource());
// 每隔一定时间模拟一次失败
DataStream<Tuple2<String, Integer>> result = countStream.map(new
CheckpointedSourceExample.FailingMapper(20));
// 类 UNIX 操作系统的临时文件夹在 /tmp 下
// Windows 用户需要修改该目录
String preCommitPath = "/tmp/flink-sink-precommit";
String commitedPath = "/tmp/flink-sink-commited";
if (!Files.exists(Paths.get(preCommitPath))) {
Files.createDirectory(Paths.get(preCommitPath));
}
if (!Files.exists(Paths.get(commitedPath))) {
Files.createDirectory(Paths.get(commitedPath));
}
// 使用 Exactly-Once 语义的 Sink,执行本程序时可以查看相应的输出目录
result.addSink(new TwoPhaseFileSink(preCommitPath, commitedPath));
// 输出数据,无 Exactly-Once 保障,有数据重发现象
result.print();
代码清单 7-5 在主逻辑中使用 Two-Phase-Commit 的 Sink
Flink 的 Kafka Sink 中的 FlinkKafkaProducer.Semantic.EXACTLY_ONCE 选项就使用这种方式实现,因为 Kafka 提供了事务机制,开发者可以通过“预提交 - 提交”的两阶段提交方式将数据写入 Kafka。但是需要注意的是,这种方式理论上能够提供百分之百的 Exactly-Once 保障,但实际执行过程中,这种方式比较依赖 Kafka 和 Flink 之间的协作,如果 Flink 作业的故障恢复时间过长会导致超时,最终会导致数据丢失。因此,这种方式只能在理论上提供百分之百的 Exactly-Once 保障。 将转化为 markdown 格式,输出源代码: