1.3. 代表性大数据技术#
MapReduce 编程模型的提出为大数据分析和处理开创了一条先河,其后涌现出一批知名的开源大数据技术,本节主要对一些流行的技术和框架进行简单介绍。
Hadoop#
2004 年,Hadoop 的创始人道格·卡廷(Doug Cutting)和麦克·卡法雷拉(Mike Cafarella)受 MapReduce 编程模型和 Google File System 等技术的启发,对其中提及的思想进行了编程实现,Hadoop 的名字来源于道格 · 卡廷儿子的玩具大象。由于道格 · 卡廷后来加入了雅虎,并在雅虎工作期间做了大量 Hadoop 的研发工作,因此 Hadoop 也经常被认为是雅虎开源的一款大数据框架。时至今日,Hadoop 不仅是整个大数据领域的先行者和领航者,更形成了一套围绕 Hadoop 的生态圈,Hadoop 和它的生态圈是绝大多数企业首选的大数据解决方案。图 1.7 展示了 Hadoop 生态圈一些流行组件。
Hadoop 生态圈的核心组件主要有如下 3 个。
Hadoop MapReduce:Hadoop 版本的 MapReduce 编程模型,可以处理海量数据,主要面向批处理。
HDFS:HDFS(Hadoop Distributed File System)是 Hadoop 提供的分布式文件系统,有很好的扩展性和容错性,为海量数据提供存储支持。
YARN:YARN(Yet Another Resource Negotiator)是 Hadoop 生态圈中的资源调度器,可以管理一个 Hadoop 集群,并为各种类型的大数据任务分配计算资源。
这三大组件中,数据存储在 HDFS 上,由 MapReduce 负责计算,YARN 负责集群的资源管理。除了三大核心组件,Hadoop 生态圈还有很多其他著名的组件,部分如下。
Hive:借助 Hive,用户可以编写结构化查询语言(Structured Query Language,SQL)语句来查询 HDFS 上的结构化数据,SQL 语句会被转化成 MapReduce 运行。
HBase:HDFS 可以存储海量数据,但访问和查询速度比较慢,HBase 可以提供给用户毫秒级的实时查询服务,它是一个基于 HDFS 的分布式数据库。HBase 最初受 Google Bigtable 技术的启发。
Kafka:Kafka 是一款流处理框架,主要用作消息队列。
ZooKeeper:Hadoop 生态圈中很多组件使用动物来命名,形成了一个大型 “动物园”,ZooKeeper 是这个动物园的管理者,主要负责分布式环境的协调。
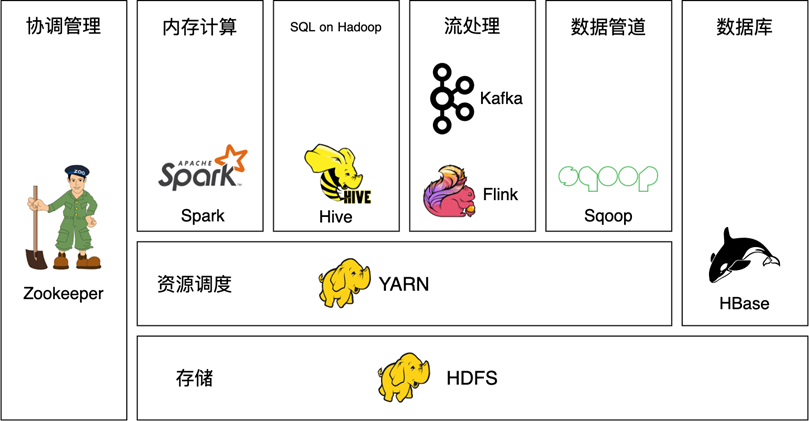
图 1.7 Hadoop 生态圈#
Spark#
2009 年,Spark 诞生于加州大学伯克利分校,2013 年被捐献给 Apache 基金会。实际上,Spark 的创始团队本来是为了开发集群管理框架 Apache Mesos(以下简称 Mesos)的,其功能类似 YARN,Mesos 开发完成后,需要一个基于 Mesos 的产品运行在上面以验证 Mesos 的各种功能,于是他们接着开发了 Spark。Spark 有火花、鼓舞之意,创始团队希望用 Spark 来证明在 Mesos 上从零开始创造一个项目非常简单。
Spark 是一款大数据处理框架,其开发初衷是改良 Hadoop MapReduce 的编程模型和提高运行速度,尤其是提升大数据在机器学习方向上的性能。与 Hadoop 相比,Spark 的改进主要有如下两点。
易用性:MapReduce 模型比 MPI 更友好,但仍然不够方便。因为并不是所有计算任务都可以被简单拆分成 Map 和 Reduce,有可能为了解决一个问题,要设计多个 MapReduce 任务,任务之间相互依赖,整个程序非常复杂,导致代码的可读性和可维护性差。Spark 提供更加方便易用的接口,提供 Java、Scala、Python 和 R 语言等的 API,支持 SQL、机器学习和图计算,覆盖了绝大多数计算场景。
速度快:Hadoop 的 Map 和 Reduce 的中间结果都需要存储到磁盘上,而 Spark 尽量将大部分计算放在内存中。加上 Spark 有向无环图的优化,在官方的基准测试中,Spark 比 Hadoop 快一百倍以上。
Spark 的核心在于计算,主要目的在于优化 Hadoop MapReduce 计算部分,在计算层面提供更细致的服务。
Spark 并不能完全取代 Hadoop,实际上,从 图 1.7 可以看出,Spark 融入了 Hadoop 生态圈,成为其中的重要一员。一个 Spark 任务很可能依赖 HDFS 上的数据,向 YARN 申请计算资源,将结果输出到 HBase 上。当然,Spark 也可以不用依赖这些组件,独立地完成计算。
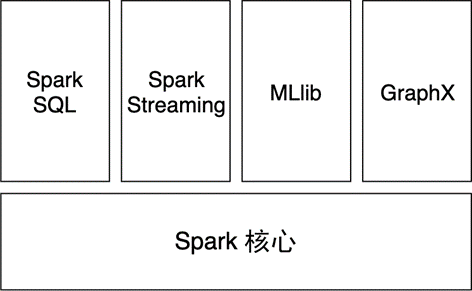
图 1.8 Spark 生态圈#
Spark 主要面向批处理需求,因其优异的性能和易用的接口,Spark 已经是批处理界绝对的 “王者”。Spark 的子模块 Spark Streaming 提供了流处理的功能,它的流处理主要基于 mini-batch 的思想。如 图 1.9 所示,Spark Streaming 将输入数据流切分成多个批次,每个批次使用批处理的方式进行计算。因此,Spark 是一款集批处理和流处理于一体的处理框架。

图 1.9 Spark Streaming mini-batch 处理#
Apache Kafka#
2010 年,LinkedIn 开始了其内部流处理框架的开发,2011 年将该框架捐献给了 Apache 基金会,取名 Apache Kafka(以下简称 Kafka)。Kafka 的创始人杰 · 克雷普斯(Jay Kreps)觉得这个框架主要用于优化读写,应该用一个作家的名字来命名,加上他很喜欢作家卡夫卡的文学作品,觉得这个名字对一个开源项目来说很酷,因此取名 Kafka。
Kafka 也是一种面向大数据领域的消息队列框架。在大数据生态圈中,Hadoop 的 HDFS 或 Amazon S3 提供数据存储服务,Hadoop MapReduce、Spark 和 Flink 负责计算,Kafka 常常用来连接不同的应用系统。
如 图 1.10 所示,企业中不同的应用系统作为数据生产者会产生大量数据流,这些数据流还需要进入不同的数据消费者,Kafka 起到数据集成和系统解耦的作用。系统解耦是让某个应用系统专注于一个目标,以降低整个系统的维护难度。在实践上,一个企业经常拆分出很多不同的应用系统,系统之间需要建立数据流管道(Stream Pipeline)。假如没有 Kafka 的消息队列,M 个生产者和 N 个消费者之间要建立 M×N 个点对点的数据流管道,Kafka 就像一个中介,让数据管道的个数变为 M+N,大大减小了数据流管道的复杂程度。
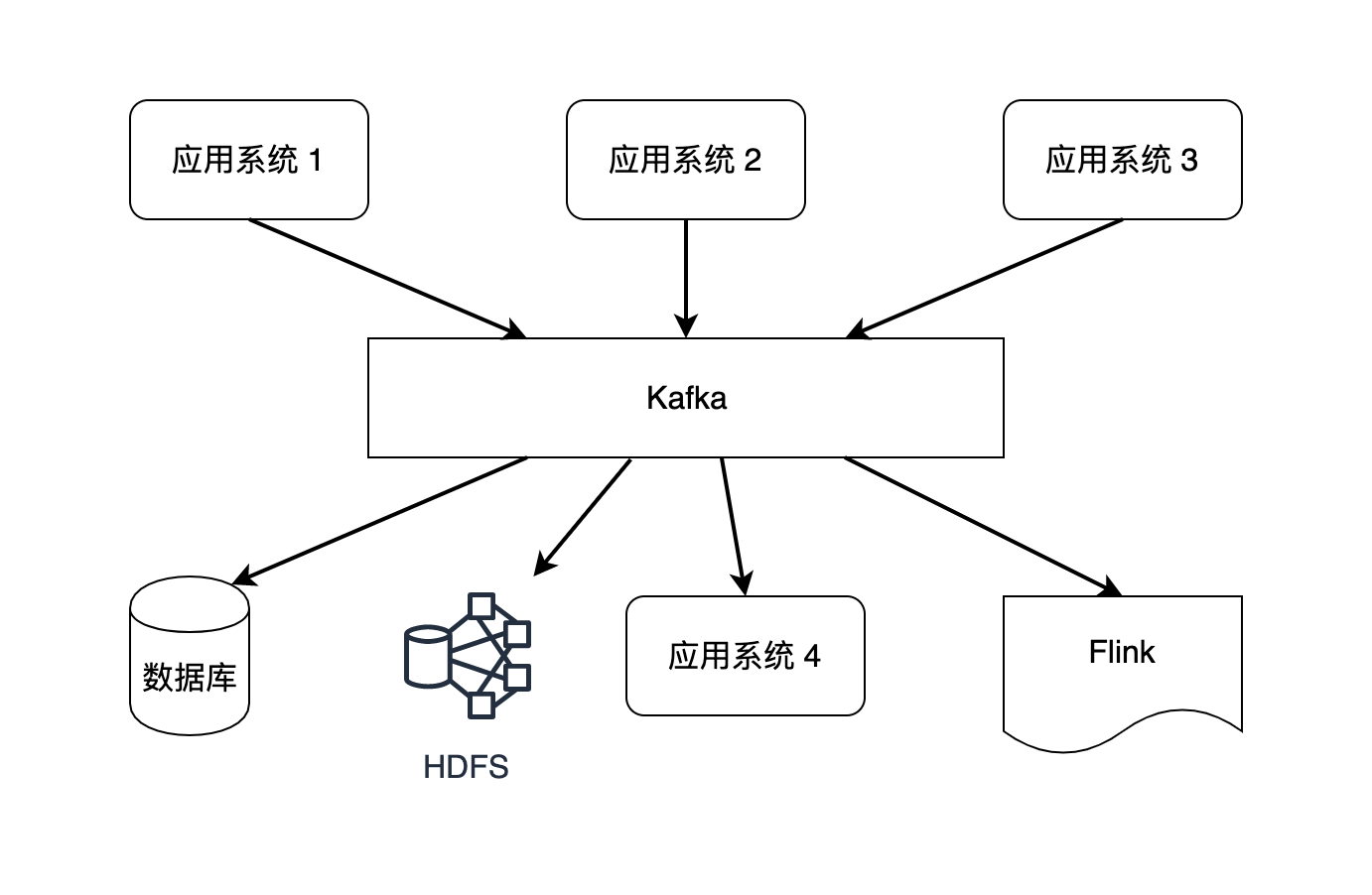
图 1.10 Kafka 可以连接多个应用系统#
从批处理和流处理的角度来讲,数据流经 Kafka 后会持续不断地写入 HDFS,积累一段时间后可提供给后续的批处理任务,同时数据流也可以直接流入 Flink,被用于流处理。
随着流处理的兴起,Kafka 不甘心只做一个数据流管道,开始向轻量级流处理方向努力,但相比 Spark 和 Flink 这样的计算框架,Kafka 的主要功能侧重在消息队列上。
Flink#
Flink 是由德国 3 所大学发起的的学术项目,后来不断发展壮大,并于 2014 年年末成为 Apache 顶级项目之一。在德语中,“flink” 表示快速、敏捷,以此来表征这款计算框架的特点。
Flink 主要面向流处理,如果说 Spark 是批处理界的 “王者”,那么 Flink 就是流处理领域冉冉升起的 “新星”。流处理并不是一项全新的技术,在 Flink 之前,不乏流处理引擎,比较著名的有 Storm、Spark Streaming,图 1.11 展示了流处理框架经历的三代演进。
2011 年成熟的 Apache Strom(以下简称 Storm)是第一代被广泛采用的流处理引擎。它是以数据流中的事件为最小单位来进行计算的。以事件为单位的框架的优势是延迟非常低,可以提供毫秒级的延迟。流处理结果依赖事件到达的时序准确性,Storm 并不能保障处理结果的一致性和准确性。Storm 只支持至少一次(At-Least-Once)和至多一次(At-Most-Once),即数据流里的事件投递只能保证至少一次或至多一次,不能保证只有一次(Exactly-Once)。在多项基准测试中,Storm 的数据吞吐量和延迟都远逊于 Flink。对于很多对数据准确性要求较高的应用,Storm 有一定劣势。此外,Storm 不支持 SQL,不支持中间状态(State)。

图 1.11 流处理框架演进#
2013 年成熟的 Spark Streaming 是第二代被广泛采用的流处理框架。1.3.2 小节中提到,Spark 是 “一统江湖” 的大数据处理框架,Spark Streaming 采用微批次(mini-batch)的思想,将数据流切分成一个个小批次,一个小批次里包含多个事件,以接近实时处理的效果。这种做法保证了 “Exactly-Once” 的事件投递效果,因为假如某次计算出现故障,重新进行该次计算即可。Spark Streaming 的 API 相比第一代流处理框架更加方便易用,与 Spark 批处理集成度较高,因此 Spark 可以给用户提供一个流处理与批处理一体的体验。但因为 Spark Streaming 以批次为单位,每次计算一小批数据,比起以事件为单位的框架来说,延迟从毫秒级变为秒级。
与前两代引擎不同,在 2015 年前后逐渐成熟的 Flink 是一个支持在有界和无界数据流上做有状态计算的大数据处理框架。它以事件为单位,支持 SQL、状态、水位线(Watermark)等特性,支持 “Exactly-Once”。比起 Storm,它的吞吐量更高,延迟更低,准确性能得到保障;比起 Spark Streaming,它以事件为单位,达到真正意义上的实时计算,且所需计算资源相对更少。具体而言,Flink 的优点如下。
支持事件时间(Event Time)和处理时间(Processing Time)多种时间语义。即使事件乱序到达,Event Time 也能提供准确和一致的计算结果。Procerssing Time 适用于对延迟敏感的应用。
Exactly-Once 投递保障。
毫秒级延迟。
可以扩展到上千台节点、在阿里巴巴等大公司的生产环境中进行过验证。
易用且多样的 API,包括核心的 DataStream API 和 DataSet API 以及 Table API 和 SQL。
可以连接大数据生态圈各类组件,包括 Kafka、Elasticsearch、JDBC、HDFS 和 Amazon S3。可以运行在 Kubernetes、YARN、Mesos 和独立(Standalone)集群上。