9.2. 配置文件#
在前文的介绍中,我们曾多次提到 Flink 主目录下的 conf/flink-conf.yaml 文件,这个文件在作业配置中起到了至关重要的作用。
flink-conf.yaml 是一个 YAML 配置文件,文件里使用 Key-Value 来设置一些参数。这个文件会被很多 Flink 进程读取,文件改动后,相关进程必须重启才能生效。例如,9.1 节中提到,Standalone 集群使用 bin/start-cluster.sh 脚本启动时,会读取 Master 的 IP 地址等。从官网下载的 flink-conf.yaml 文件已经对一些参数做了配置,这些配置主要针对的是单机环境,如果用户在集群环境中使用它,就需要修改一些配置。
本节将从 Java、CPU、内存、磁盘等几大方向来介绍一些常用的配置。由于配置众多,无法一一列举,用户需要阅读 Flink 官方文档来进行更多个性化配置。
Java 和类加载#
在安装 Java 时,我们一般会将 Java 的路径以 $JAVA_HOME 的形式添加到环境变量 $PATH 中,默认情况下,Flink 使用环境变量中的 Java 来运行程序。或者在 flink-conf.yaml 中设置 env.java.home 参数,使用安装到某个位置的 Java。
env.java.opts 设置所有 Flink JVM 进程参数,env.java.opts.jobmanager 和 env.java.opts.taskmanager 分别设置 JobManager 和 TaskManager 的 JVM 进程参数。下面的配置使得所有 Flink JVM 进程使用并发垃圾回收器。
env.java.opts: -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75
类加载(Classloading)对于很多应用开发者来说可能不需要过多关注,但是对于框架开发者来说需要非常小心。类加载的具体作用是将 Java 的 .class 文件加载到 JVM 虚拟机中。我们知道,当 Java 程序启动时,要使用 -classpath 参数设置从某些路径上加载所需要的依赖包。
$ java -classpath ".;./lib/*"
上面的命令将当前目录 . 和当前目录下的文件夹 ./lib 两个路径加载进来,两个路径中的包都能被引用。一个 Java 程序需要引用的类库和包很多,包括 JDK 核心类库和各种第三方类库,JVM 启动时,并不会一次性加载所有 JAR 包中的 .class 文件,而是动态加载。一个 Flink 作业一般主要加载下面两种类。
Java Classpath:包括 JDK 核心类库和 Flink 主目录下
lib文件夹中的类,其中lib文件夹中一般包含一些第三方依赖,比如 Hadoop 依赖。用户类(User Code):用户编写的应用作业中的类,这些用户源码被打成 JAR 包,每提交一个作业时,相应的 JAR 包会被提交。
向集群提交一个 Flink 作业时,Flink 会动态加载这些类,隐藏一些不必要的依赖,以尽量避免依赖冲突。常见的类依赖加载策略有两种:子类优先(Child-first)和父类优先(Parent-first)。
Child-first:Flink 会优先加载用户编写的应用作业中的类,然后再加载 Java Classpath 中的类。Parent-first:Flink 会优先加载 Java Classpath 中的类。Flink 默认使用 Child-first 策略,
flink-conf.yaml的配置为:classloader.resolve-order: child-first。这种策略的好处是,用户在自己的应用作业中所使用的类库可以和 Flink 核心类库不一样,在一定程度上避免依赖冲突。这种策略适合绝大多数情况。
但是,Child-first 策略在个别情况下也有可能出问题,这时候需要使用 Parent-first 策略,flink-conf.yaml 的配置为:classloader.resolve-order: parent-first。Parent-first 也是 Java 默认的类加载策略。
Note
有些类加载的过程中总会使用 Parent-first 策略。classloader.parent-first-patterns.default 配置了必须使用 Parent-first 策略的类,如下。
java.;scala.;org.apache.flink.;com.esotericsoftware.kryo;org.apache.hadoop.;
javax.annotation.;org.slf4j;org.apache.log4j;org.apache.logging;org.apache.
commons.logging;ch.qos.logback;org.xml;javax.xml;org.apache.xerces;org.w3c
classloader.parent-first-patterns.default 列表最好不要随便改动,如果想要添加一些需要使用 Parent-first 的类,应该将那些类放在 classloader.parent-first-patterns.additional 中,类之间用分号 ; 隔开。在加载过程中,classloader.parent-first-patterns.additional 列表中的类会追加到 classloader.parent-first-patterns.default 列表后。
并行度与槽位划分#
在第 3 章中我们已经介绍过 Flink 的 JobManager 和 TaskManager 的功能,其中 TaskManager 运行具体的计算。每个 TaskManager 占用一定的 CPU 和内存资源,一个 TaskManager 会被切分为一到多个 Slot,Slot 是 Flink 运行具体计算任务的最小单元。如果一个作业不进行任何优化,作业中某个算子的子任务会被分配到一个 Slot 上,这样会产生资源浪费。9.3 节会介绍,多个子任务可以连接到一起,放在一个 Slot 中运行。最理想的情况下,一个 Slot 上运行着一个作业所有算子组成的流水线(Pipeline)。
前文中我们曾多次提到并行度的概念:如果一个作业的并行度为 parallelism,那么该作业的每个算子都会被切分为 parallelism 个子任务。如果作业开启了算子链和槽位共享,那么这个作业需要 parallelism 个 Slot。所以说,一个并行度为 parallelism 的作业至少需要 parallelism 个 Slot。
在 flink-conf.yaml 中,taskmanager.numberOfTaskSlots 配置一个 TaskManager 可以划分成多少个 Slot。默认情况下它的值为 1。对于 Standalone 集群来说,官方建议将参数值配置为与 CPU 核心数相等或成比例。例如,这个参数值可以配置为 CPU 核心数或 CPU 核心数的一半。TaskManager 的内存会平均分配给每个 Slot,但并没有将某个 CPU 核心绑定到某个 Slot 上。或者说,TaskManager 中的多个 Slot 是共享多个 CPU 核心的,每个 Slot 获得 TaskManager 中内存的一部分。
关于如何配置 taskmanager.numberOfTaskSlots 参数,其实并没有一个绝对的准则。每个 TaskManager 下有一个 Slot,那么该 Slot 会独立运行在一个 JVM 进程中;每个 TaskManager 下有多个 Slot,那么多个 Slot 同时运行在一个 JVM 进程中。TaskManager 中的多个 Slot 可以共享 TCP 连接、“心跳信息”以及一些数据结构,这在一定程度上减少了一些不必要的消耗。但是,我们要知道,Slot 是以线程为基本计算单元的,线程的隔离性相对较差,一个线程中的错误可能导致整个 JVM 进程崩溃,运行在其上的其他 Slot 也会被波及。假如一个 TaskManager 下只有一个 Slot,因为 TaskManager 是一个进程,进程之间的隔离度较好,但这种方式下,作业性能肯定会受到影响。
Standalone 集群一般部署在物理机或多核虚拟机上,对 CPU 的资源划分粒度比较粗,所以官方建议把 taskmanager. numberOfTaskSlots 参数值配置为 CPU 核心数。YARN 和 Kubernetes 这些调度平台对资源的划分粒度更细,可以精确地将 CPU 核心分配给 Container,比如可以配置单 CPU 的 Container 节点给只有一个 Slot 的 TaskManager 使用。Flink YARN 可以使用 yarn.containers.vcores 配置每个 Container 中 CPU 核心的数量,默认情况下它的值等于 taskmanager.numberOfTaskSlots。Flink Kubernetes 可以使用 kubernetes.taskmanager.cpu 配置单个 TaskManager 的 CPU 数量,默认情况下它的值等于 taskmanager.numberOfTaskSlots。
总结下来,关于计算的并行划分,有两个参数是可以配置的:作业并行度和 TaskManager 中 Slot 的数量。作业的并行度可以在用户代码中配置,也可以在提交作业时通过命令行参数配置。TaskManager 中 Slot 数量通过 taskManager.numberOfTaskSlots 配置。假设作业开启了算子链和槽位共享,该作业的 TaskManager 数量为:
可以肯定的是,作业并行划分并不能一蹴而就,需要根据具体情况经过一些调优后才能达到最佳状态。这包括使用何种部署方式、部署时如何给 TaskManager 划分资源、如何配置 `taskManager.
numberOfTaskSlots`,以及如何进行 JVM 调优等。在 YARN 和 Kubernetes 这样的部署环境上,一个简单、易上手的部署方式是:配置 `taskmanager.numberOfTaskSlots` 为 1,给每个 Container 申请的 CPU 数量也为 1,提交作业时根据作业的数据量大小配置并行度。Flink 会根据上述参数分配足够的 TaskManager 运行该作业。
内存#
堆区内存和堆外内存#
内存管理是每个 Java 开发者绕不开的话题。在 JVM 中,内存一般分为堆区(On-heap 或 Heap)内存和堆外(Off-heap)内存。在一个 JVM 程序中,堆区是被 JVM 虚拟化之后的内存空间,里面存放着绝大多数 Java 对象的实例,被所有线程共享。Java 使用垃圾回收(Garbage Collection,GC)机制来清理内存中的不再使用的对象,堆区是垃圾回收的主要工作区域。内存经过垃圾回收之后,会产生大量不连续的空间,在某个时间点,JVM 必须进行一次彻底的垃圾回收(Full GC)。Full GC 时,垃圾回收器会对所有分配的堆区内存进行完整的扫描,扫描期间,绝大多数正在运行的线程会被暂时停止。这意味着,一次 Full GC 对一个 Java 应用造成的影响,跟堆区内存所存储的数据多少是成正比的,过大的堆区内存会影响 Java 应用的性能。例如,一个 Java 应用的堆区内存大小大于 100GB,Full GC 会产生分钟级的卡顿。
然而,在大数据时代,一个 Java 应用的堆区内存需求会很大,使用超过 100GB 大小的内存的情况比比皆是。因此,如果一个程序只使用堆区内存会产生一个悖论,即如果开辟的堆区内存过小,数据超过了内存限制,会抛出 OutOfMemoryError 异常(简称 OOM 问题),影响系统的稳定;如果堆区内存过大,GC 时会经常卡顿,影响系统的性能。一种解决方案是将一部分内存对象迁移到堆外内存上。堆外内存直接受操作系统管理,可以被其他进程和设备访问,可以方便地开辟一片很大的内存空间,又能解决 GC 带来的卡顿问题,特别适合读 / 写操作比较频繁的场景。堆外内存虽然强大,但也有其负面影响,比如:堆外内存的使用、监控和调试更复杂,一些操作在堆外内存上会比较慢。
图 9.5 是对 Flink 内存模型的划分示意图。无论 Flink 的 JobManager 还是 TaskManager 都是一个 JVM 进程,整个 Flink JVM 进程的内存(见 图 9.5 中 Total Process Memory 部分)包括两大部分:Flink 占用的内存(见 图 9.5 中 Total Flink Memory 部分)和 JVM 相关内存(图 9.5 中 JVM Specific Memory 部分)。JVM Specific Memory 是绝大多数 Java 程序都需要的一块内存区域,比如各个类的元数据会放在该区域。Total Flink Memory 是 Flink 能使用到的内存,Total Flink Memory 又包括 JVM 堆区内存(见 图 9.5 中 JVM Heap 部分)和堆外内存(见 图 9.5 中 Off-heap Memory 部分)。Off-heap Memory 包括一些 Flink 所管理的内存(见 图 9.5 中 Flink Managed Memory 部分),一般主要在 TaskManager 上给个别场景使用,Off-heap Memory 另外一部分主要给网络通信缓存使用的内存(见 图 9.5 中 Direct Memory)。
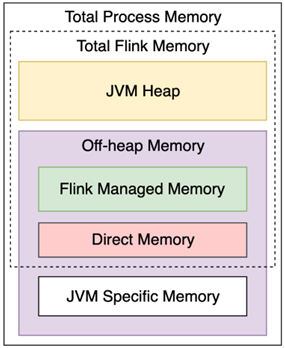
图 9.5 Flink 内存模型#
Note
Flink 1.10 开始对内存管理和设置进行了一次较大改动,相关的配置与之前的版本有明显不同,这里只介绍 Flink 1.10 版本以后的内存配置方法。从老版本迁移过来的朋友也应该注意修改内存配置,否则会出现错误。
从框架的角度来看,Flink 将内存管理部分做了封装,用户在绝大多数情况下其实可以不用关注数据到底是如何写入内存的。但对于一些数据量较大的作业,了解 Flink 的内存模型还是非常有必要的。
Master 的内存配置#
在具体的内存管理问题上,Flink 的 Master 和 TaskManager 有所区别。Master 中的组件虽然比较多,但是整体来说占用内存不大。ResourceManager 主要负责计算资源的管理、Dispatcher 负责作业分发、JobManager 主要协调某个作业的运行,这些组件无须直接处理数据。TaskManager 主要负责数据处理。相比之下,Master 对内存的需求没有那么苛刻,TaskManager 对内存的需求很高。
一个最简单的配置方法是设置 Master 进程的 Total Process Memory,参数项为 jobmanager.memory.process.size。配置好 Total Process Memory 后,Flink 有一个默认的分配比例,会将内存分配给各个子模块。另一个比较方便的方式是设置 Total Flink Memory,即 Flink 可用内存,参数项为 jobmanager.memory.flink.size。Total Flink Memory 主要包括了堆区内存和堆外内存。堆区内存包含了 Flink 框架运行时本身所占用的内存空间,也包括 JobManager 运行过程中占用的内存。如果 Master 进程需要管理多个作业(例如 Session 部署模式下),或者某个作业比较复杂,作业中有多个算子,可以考虑增大 Total Flink Memory。
TaskManager 的内存配置#
因为 TaskManager 涉及大规模数据处理,TaskManager 的内存配置需要用户花费更多的精力。TaskManager 的内存模型主要包括图 9-6 所示的组件。
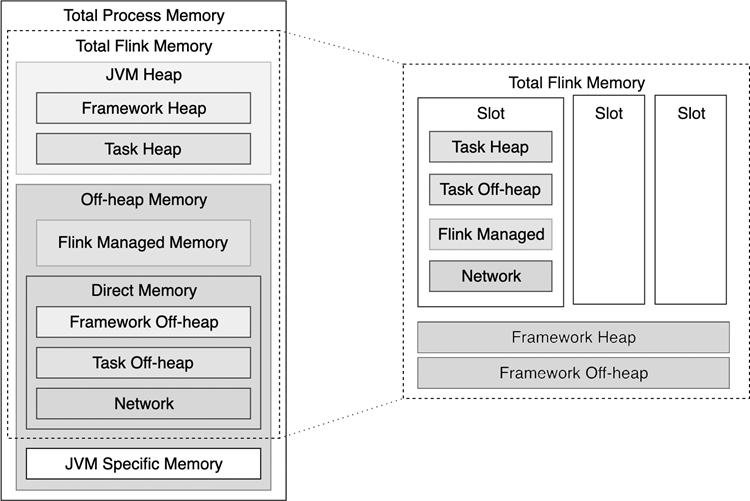
图 9.6 TaskManager 内存模型#
如 图 9.6 右侧所示单独对 Total Flink Memory 做了拆解。Total Flink Memory 又包括 JVM 堆区内存和堆外内存。无论是堆区内存还是堆外内存,一部分是 Flink 框架所占用的,即 Framework Heap 和 Framework Off-heap,这部分内存在计算过程中是给 Flink 框架使用的,作业实际所用到的 Slot 无法占用这部分资源。Flink 框架所占用的内存一般比较固定。另一部分是当前计算任务所占用的,即 Task Heap、Task Off-heap、Flink Managed Memory 和 Network。一个用户作业的绝大多数用户代码都运行在 Task Heap 区,因此 Task Heap 区的大小需要根据用户作业调整。
Flink 专门开辟了一块堆外内存(见图 9-6 所示的 Flink Managed Memory 部分),用来管理一部分特殊的数据。Flink Managed Memory 主要用途为:流处理下 RocksDB 的 State Backend,批处理下排序、中间数据缓存等。RocksDB 是第三方的插件,它不占用堆区内存。而 MemoryStateBackend 和 FsStateBackend 的本地状态是基于 Task Heap 区域的。如果流处理作业没有使用 RocksDB,或者流处理作业没有状态数据,Flink Managed Memory 这部分内存可以为零,以避免资源浪费。
Flink 的网络传输基于 Netty 库,Netty 以一块堆外内存(见图 9-6 所示的 Network 部分)作为缓存区。当 TaskManager 进程之间需要进行数据交换时,例如进行数据重分布或广播操作,数据会先缓存在 Network 区。假如数据量大,数据交换操作多,Network 区的内存压力会明显增大。
可以看到,Flink 的 TaskManager 内存模型并不简单。尽管 Flink 社区希望提供给用户最简单易用的默认配置,但使用一套配置处理各式各样的用户作业并不现实。Flink 将内存配置分为不同粒度。
粗粒度的内存配置方法:直接配置整个 TaskManager JVM 进程的内存。确切地说,是配置 Total Process Memory 或 Total Flink Memory 两者中的任意一个。这就相当于,我们配置好一个总量,其余各个子模块根据默认的比例获得其相应的内存大小。从图 9-6 中也可以看到,Total Process Memory 比 Total Flink Memory 多了 JVM Specific Memory。对于 YARN 或 Kubernetes 这种容器化的部署方式,给 Total Process Memory 申请内存更精确,相应的内存直接由资源管理器交付给了 Container。对于 Standalone 集群,给 Total Flink Memory 申请内存更合适,相应的内存直接交付给了 Flink 本身。其中,Total Process Memory 使用参数
taskmanager.memory.process.size,Total Flink Memory 使用参数taskmanager.memory.flink.size。细粒度的内存配置方法:同时配置 Task Heap 和 Flink Managed Memory 两个内存。根据前文的介绍,Task Heap 和 Flink Managed Memory 不涉及 Flink 框架所需内存,不涉及 JVM 所需内存,它们只服务于某个计算任务。这个方法可以更明确地为最需要动态调整内存的地方分配资源,而其他组件会根据比例自动调整。其中,Task Heap 由
taskmanager.memory.task.heap.size参数配置,Flink Managed Memory 由taskmanager.memory.managed.size参数配置。
至此,我们介绍了 3 种内存配置方法:两种方法从宏观角度配置内存总量,一种方法从用户作业角度配置该作业所需量。涉及下面几个参数。
taskmanager.memory.process.size:Total Process Memory,包括 Flink 内存和 JVM 内存,是一个进程内存消耗的总量,各子模块会按照比例配置,常用在容器化部署方式上。taskmanager.memory.flink.size:Total Flink Memory,不包括 JVM 内存,只关乎 Flink 部分,其他模块会按照比例配置,常用在 Standalone 集群部署方式上。taskmanager.memory.task.heap.size和taskmanager.memory.managed.size:两个参数必须同时配置,细粒度地配置了一个作业所需内存,其他模块会按照比例配置。
Note
这 3 个参数不要同时配置,否则会引起冲突,导致作业运行失败。我们应该在这 3 个参数中选择一个来配置。
综上,FlinkFlink 提供了大量的配置参数帮用户处理内存问题,但是实际场景千变万化,很难一概而论,内存的配置和调优也需要用户不断摸索和尝试。
磁盘#
Flink 进程会将一部分数据写入本地磁盘,比如:日志信息、RocksDB 数据等。 io.tmp.dirs 参数配置了数据写入本地磁盘的位置。该参数所指目录中存储了 RocksDB 创建的文件、缓存的 JAR 包,以及一些中间计算结果。默认使用了 JVM 的参数 java.io.tmpdir,而该参数在 Linux 操作系统一般指的是 /tmp 目录。YARN、Kubernetes 等会使用 Container 平台的临时目录作为该参数的默认值。
Note
io.tmp.dirs 中存储的数据并不是用来做故障恢复的,但是如果这里的数据被清理,会对故障恢复产生较大影响。很多 Linux 发行版默认会定期清理 /tmp 目录,如果要在该操作系统上部署长期运行的 Flink 流处理作业,一定要记得将定期清理的开关关掉。