2.4. 案例实战:Flink 开发环境搭建#
本案例实战主要带领读者完成对 Flink 开发环境的搭建。
准备所需软件#
在 1.7 节中我们简单提到了 Kafka 的安装部署所需的软件环境,这里我们再次梳理一下 Flink 开发所需的软件环境。
操作系统
目前,我们可以在 Linux、macOS 和 Windows 操作系统上开发和运行 Flink。类 UNIX 操作系统(Linux 或 macOS)是大数据首选的操作系统,它们对 Flink 的支持更好,适合进行 Flink 学习和开发。后文会假设读者已经拥有了一个类 UNIX 操作系统。Windows 用户为了构建一个类 UNIX 环境,可以使用专门为 Linux 操作系统打造的子系统(Windows subsystem for Linux,即 WSL)或者是 Cygwin,又或者创建一个虚拟机,在虚拟机中安装 Linux 操作系统。
JDK
和 Kafka 一样,Flink 开发基于 JDK,因此也需要提前安装好 JDK 1.8+ (Java 8 或更高的版本),配置好 Java 环境变量。
其他工具
其他的工具因开发者习惯不同来安装,不是 Flink 开发所必需的,但这里仍然建议提前安装好以下工具。
Apache Maven 3.0+
Apache Maven 是一个项目管理工具,可以对 Java 或 Scala 项目进行构建及依赖管理,是进行大数据开发必备的工具。这里推荐使用 Maven 是因为 Flink 源码工程和本书的示例代码工程均使用 Maven 进行管理。
IntelliJ IDEA
IntelliJ IDEA 是一个非常强大的编辑器和开发工具,内置了 Maven 等一系列工具,是大数据开发必不可少的利器。Intellij IDEA 本来是一个商业软件,它提供了社区免费版本,免费版本已经基本能满足绝大多数的开发需求。
除 IntelliJ IDEA 之外,还有 Eclipse IDE 或 NetBeans IDE 等开发工具,读者可以根据自己的使用习惯选择。由于 IntelliJ IDEA 对 Scala 的支持更好,本书建议读者使用 IntelliJ IDEA。
下载并安装 Flink#
从 Flink 官网下载编译好的 Flink 程序,把下载的.tgz 压缩包放在你想放置的目录。在下载时,Flink 提供了不同的选项,包括 Scala 2.11、Scala 2.12、源码版等。其中,前两个版本是 Flink 官方提供的可执行版,解压后可直接使用,无须从源码开始编译打包。Scala 不同版本间兼容性较差,对于 Scala 开发者来说,需要选择自己常用的版本,对于 Java 开发者来说,选择哪个 Scala 版本区别不大。本书写作时,使用的是 Flink 1.11 和 Scala 2.11,读者可以根据自身情况下载相应版本。
按照下面的方式,解压该压缩包,进入解压目录,并启动 Flink 集群。
$ tar -zxvf flink-1.11.2-bin-scala_2.11.tgz # 解压
$ cd flink-1.11.2-bin-scala_2.11 # 进入解压目录
$ ./bin/start-cluster.sh # 启动 Flink 集群
成功启动后,打开浏览器,输入 http://localhost:8081,可以进入 Flink 集群的仪表盘(WebUI),如 图 2.4 所示。Flink WebUI 可以对 Flink 集群进行管理和监控。
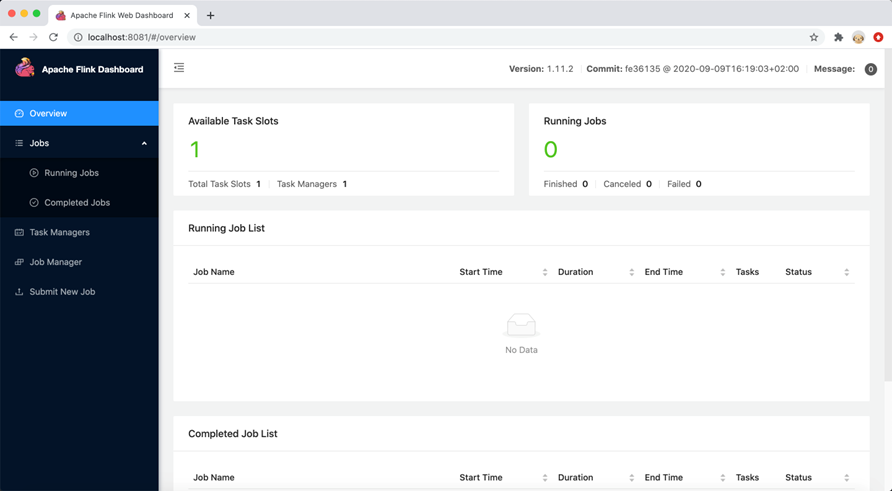
图 2.4 Flink WebUI#
创建 Flink 工程#
我们使用 Maven 从零开始创建一个 Flink 工程。
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.11.2 \
-DgroupId=com.myflink \
-DartifactId=flink-study-scala \
-Dversion=0.1 \
-Dpackage=quickstart \
-DinteractiveMode=false
archetype 是 Maven 提供的一种项目模板,是别人提前准备好了的项目的结构框架,用户只需要使用 Maven 工具下载这个模板,在这个模板的基础上丰富并完善代码逻辑。主流框架一般都准备好了 archetype,如 Spring、Hadoop 等。
不熟悉 Maven 的读者可以先使用 IntelliJ IDEA 内置的 Maven 工具,熟悉 Maven 的读者可直接跳过这部分。
如 图 2.5 所示,在 IntelliJ IDEA 里依次单击“File”→“New”→“Project”,创建一个新工程。
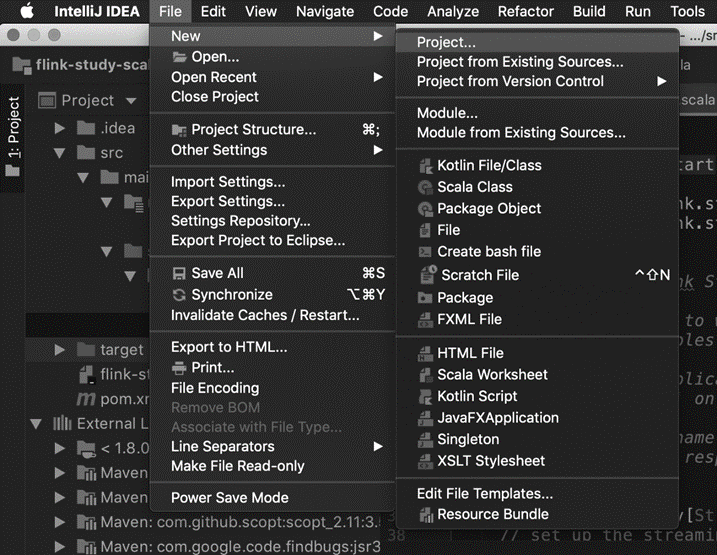
图 2.5 在 IntelliJ IDEA 中创建新工程#
如 图 2.6 所示,选择左侧的“Maven”,并勾选“Create from archetype”,并单击右侧的“Add Archetype”按钮。
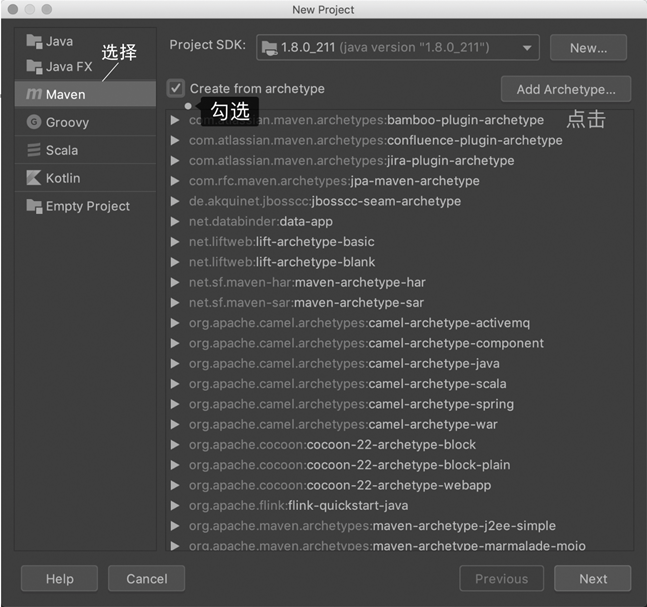
图 2.6 添加 Maven 项目#
如 图 2.7 所示,在弹出的窗口中填写 archetype 信息。其中 GroupId 为 org.apache.flink,ArtifactId 为 flink-quickstart-java,Version 为 1.11.2,然后单击“OK”。这里主要是告诉 Maven 去资源库中下载哪个版本的模板。随着 Flink 的迭代开发,Version 也在不断更新,读者可以在 Flink 的 Maven 资源库中查看最新的版本。GroupId、ArtifactId、Version 可以唯一表示一个发布出来的 Java 程序包。配置好后,单击 Next 按钮进入下一步。
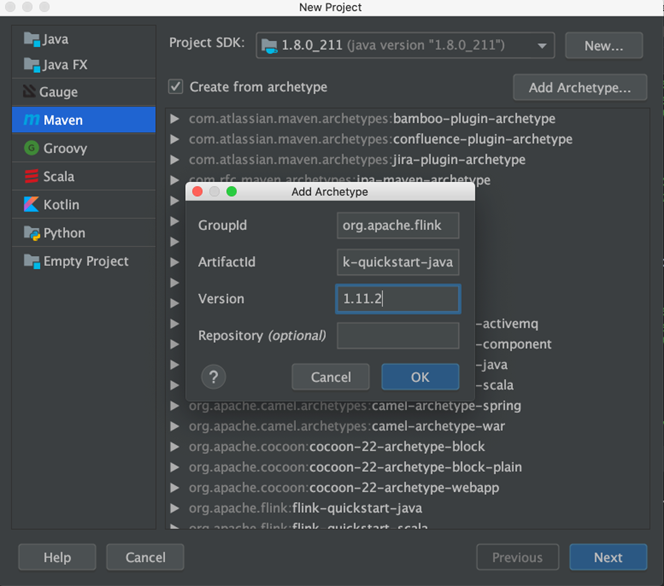
图 2.7 填写 archetype 信息#
如 图 2.8 所示,这一步是建立你自己的 Maven 工程,以区别其他 Maven 工程,GroupId 是你的公司或部门名称(可以随意填写),ArtifactId 是工程发布时的 Java 归档(Java Archive,JAR)包名,Version 是工程的版本。这些配置主要用于区别不同公司所发布的不同包,这与 Maven 和版本控制相关,Maven 的教程中都会介绍这些概念,这里不赘述。
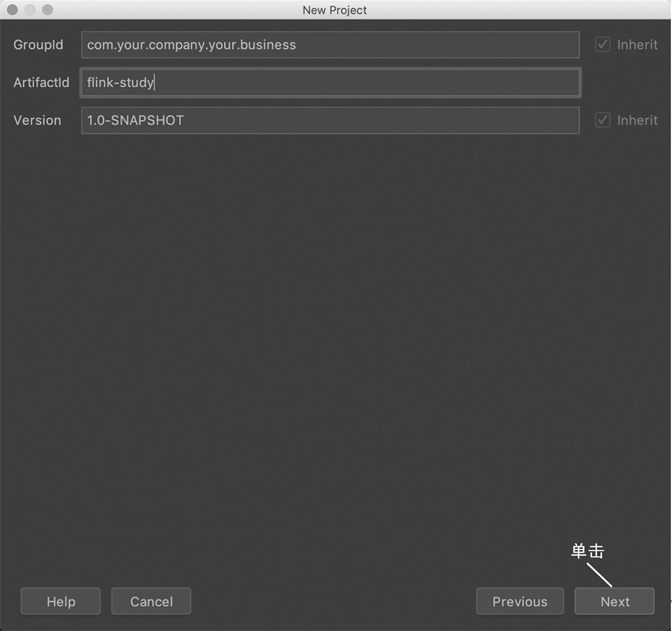
图 2.8 配置你的工程信息#
接下来可以继续单击“Next”按钮,注意最后一步选择你的工程所在的磁盘位置,单击“Finish”按钮,如 图 2.9 所示。至此,一个 Flink 模板就下载好了。
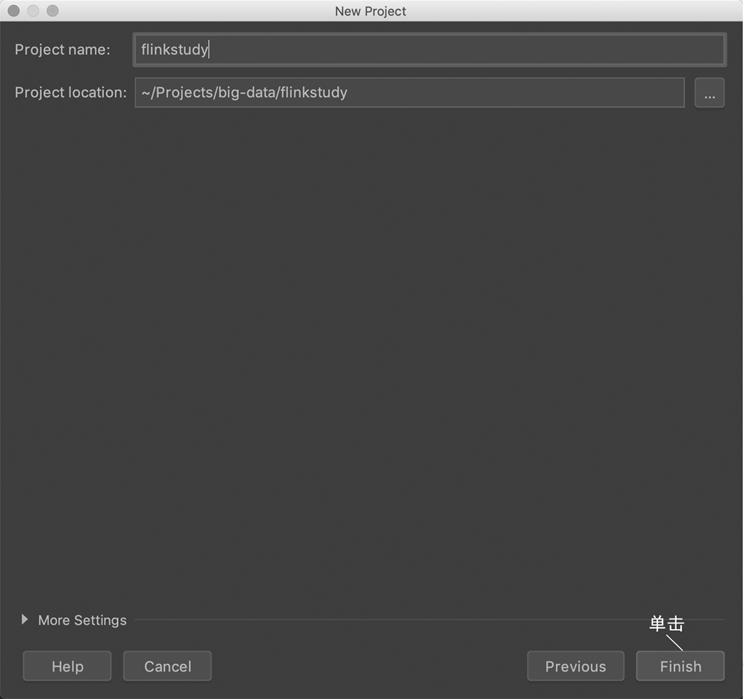
图 2.9 配置本工程的位置#
工程结构如 图 2.10 所示。左侧的“Project”栏是工程结构,其中 src/main/java 文件夹是 Java 代码文件存放位置,src/main/scala 是 Scala 代码文件存放位置。我们可以在 StreamingJob 这个文件上继续修改,也可以重新创建一个新文件。
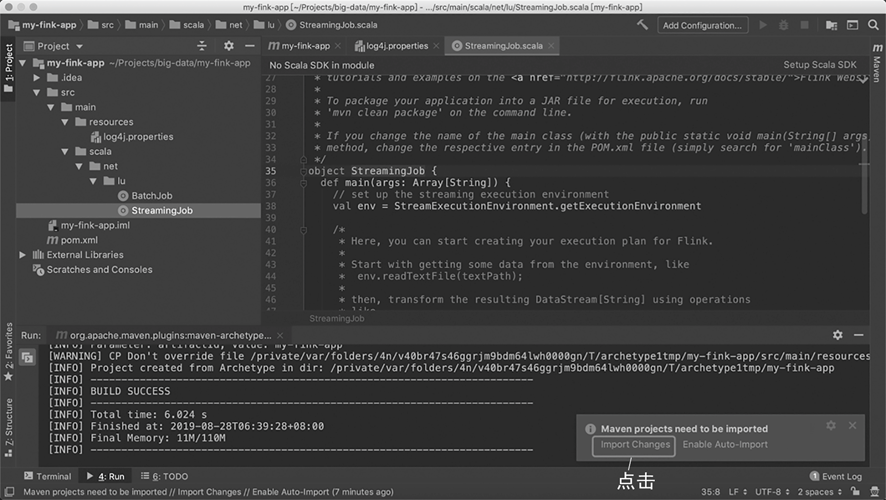
图 2.10 工程结构#
Note
开发前要单击右下角的“Import Changes”,让 Maven 导入所依赖的包。
调试和运行 Flink 程序#
我们创建一个新的文件,名为 WordCountKafkaInStdOut.java,开始编写第一个 Flink 程序—流式词频统计(WordCount)程序。这个程序接收一个 Kafka 文本数据流,进行词频统计,然后输出到标准输出上。这里先不对程序做深入分析,后文中将会做更详细的解释。
首先要设置 Flink 的运行环境。
// 设置 Flink 运行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
设置 Kafka 相关参数,连接对应的服务器和端口号,读取名为 Shakespeare 的 Topic 中的数据源,将数据源命名为 stream。
// Kafka 参数
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-group");
String inputTopic = "Shakespeare";
// Source
FlinkKafkaConsumer<String> consumer =
new FlinkKafkaConsumer<String>(inputTopic, new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(consumer);
使用 Flink API 处理这个数据流。
// Transformation
// 使用 Flink API 对输入流的文本进行操作
// 切词转换、分组、设置时间窗口、聚合
DataStream<Tuple2<String, Integer>> wordCount = stream
.flatMap((String line, Collector<Tuple2<String, Integer>> collector) -> {
String[] tokens = line.split("\\s");
// 输出结果
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<>(token, 1));
}
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
将数据流输出。
// Sink
wordCount.print();
最后运行该程序。
// execute
env.execute("kafka streaming word count");
env.execute()是启动 Flink 作业所必需的,只有在 execute() 方法被调用时,之前调用的各个操作才会被提交到集群上或本地计算机上运行。
该程序的完整代码如代码清单 2-9 所示。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class WordCountKafkaInStdOut {
public static void main(String[] args) throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// Kafka 参数
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-group");
String inputTopic = "Shakespeare";
String outputTopic = "WordCount";
// Source
FlinkKafkaConsumer<String> consumer =
new FlinkKafkaConsumer<String>(inputTopic, new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(consumer);
// Transformation
// 使用 Flink API 对输入流的文本进行操作
// 按空格切词、计数、分区、设置时间窗口、聚合
DataStream<Tuple2<String, Integer>> wordCount = stream
.flatMap((String line, Collector<Tuple2<String, Integer>> collector) -> {
String[] tokens = line.split("\\s");
// 输出结果
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<>(token, 1));
}
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
// Sink
wordCount.print();
// execute
env.execute("kafka streaming word count");
}
}
代码写完后,我们还要在 Maven 的项目对象模型(Project Object Model,POM)文件中引入下面的依赖,让 Maven 可以引用 Kafka。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
其中,${scala.binary.version} 是所用的 Scala 版本号,可以是 2.11 或 2.12,${flink.version} 是所用的 Flink 的版本号,比如 1.11.2。
运行程序#
我们在 1.7 节中展示过如何启动一个 Kafka 集群,并向某个 Topic 内发送数据流。在本次 Flink 作业启动之前,我们还要按照 1.7 节提到的方式启动一个 Kafka 集群、创建对应的 Topic,并向 Topic 中写入数据。
在 IntelliJ IDEA 中运行程序
图 2.11 在 IntelliJ IDEA 中运行 Flink 程序#
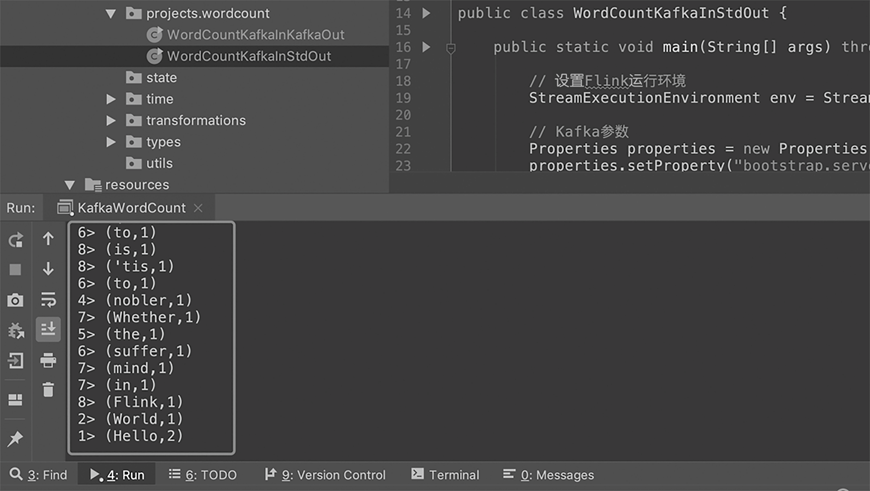
图 2.12 WordCount 程序运行结果#
恭喜你,你的第一个 Flink 程序运行成功!
Note
如果在 Intellij IDEA 中运行程序时遇到 java.lang.NoClassDefFoundError 报错,这是因为没有把依赖的类都加载进来。在 Intellij IDEA 中单击“Run”->“Edit configurations…”,在“Use classpath of module”选项上选择当前工程,并且勾选“Include dependencies with‘Provided’ Scope”
向集群提交作业
目前,我们学会了先下载并启动本地集群,接着在模板的基础上添加代码,并在 IntelliJ IDEA 中运行程序。而在生产环境中,我们一般需要将代码编译打包,提交到集群上。我们将在第 9 章详细介绍如何向 Flink 集群提交作业。
注意,这里涉及两个目录:一个是我们存放刚刚编写代码的工程目录,简称工程目录;另一个是从 Flink 官网下载解压的 Flink 主目录,主目录下的 bin 目录中有 Flink 提供的命令行工具。
进入工程目录,使用 Maven 命令行将代码编译打包。
# 使用 Maven 命令行将代码编译打包
# 打好的包一般放在工程目录的 target 目录下
$ mvn clean package
回到 Flink 主目录,使用 Flink 提供的命令行工具 flink,将打包好的作业提交到集群上。命令行的参数 –class 用来指定哪个主类作为入口。我们之后会介绍命令行的具体使用方法。
$ bin/flink run --class
com.flink.tutorials.java.api.projects.wordcount.WordCountKafkaInStdOut
/Users/luweizheng/Projects/big-data/flink-tutorials/target/flink-tutorials-0.1.jar
如图 2.13示,这时,Flink WebUI 上就多了一个 Flink 作业。
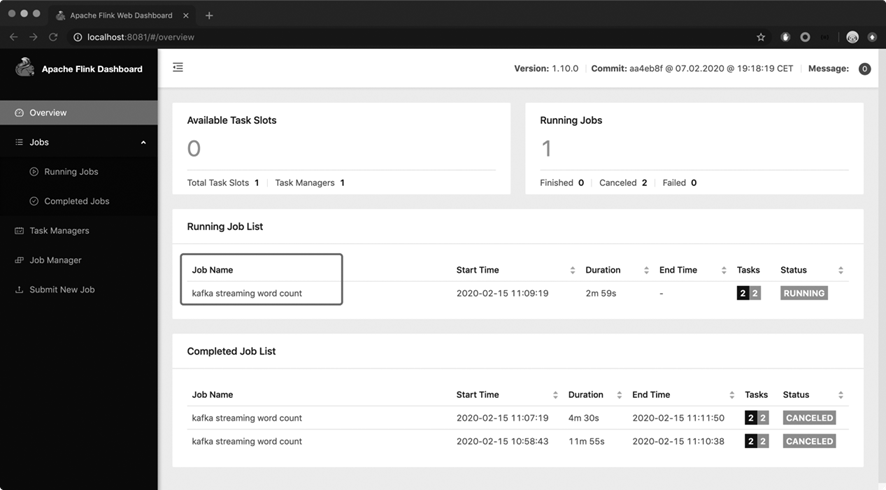
图 2.13 Flink WebUI 中多了一个 Flink 作业#
程序的输出会保存到 Flink 主目录下面的 log 目录下的.out 文件中,可以使用下面的命令查看结果。
$ tail -f log/flink-*-taskexecutor-*.out
必要时,可以使用下面的命令关停本地集群。
$ ./bin/stop-cluster.sh
Flink 开发和调试过程中,一般有如下几种方式运行程序。
使用 IntelliJ IDEA 内置的绿色运行按钮。这种方式主要在本地调试时使用。
使用 Flink 提供的命令行工具向集群提交作业,包括 Java 和 Scala 程序。这种方式更适合生产环境。
使用 Flink 提供的其他命令行工具,比如针对 Scala、Python 和 SQL 的交互式环境。
对于新手,可以先使用 IntelliJ IDEA 提供的内置运行按钮,熟练后再使用命令行工具。
本章小结#
本章中,我们回顾了 Flink 开发经常用到的继承和多态、泛型和函数式编程等概念,在本地搭建了一个 Flink 集群,创建了第一个 Flink 工程,并学会了如何运行 Flink 程序。