8.7. 用户自定义函数#
Note
本教程已出版为《Flink 原理与实践》,感兴趣的读者请在各大电商平台购买!
System Function 给我们提供了大量内置功能,但对于一些特定领域或特定场景,System Function 还远远不够,Flink 提供了用户自定义函数功能,开发者可以实现一些特定的需求。用户自定义函数需要注册到 Catalog 中,因此这类函数又被称为 Catalog Function。Catalog Function 大大增强了 Flink SQL 的表达能力。
注册函数#
在使用一个函数前,一般需要将这个函数注册到 Catalog 中。注册时需要调用 TableEnvironment 中的 registerFunction 方法。每个 TableEnvironment 都会有一个成员 FunctionCatalog,FunctionCatalog 中存储了函数的定义,当注册函数时,实际上是将这个函数名和对应的实现写入到 FunctionCatalog 中。以注册一个 ScalarFunction 为例,它在源码中如下:
FunctionCatalog functionCatalog = ...
/**
* 注册一个 ScalaFunction
* name: 函数名
* function: 一个自定义的 ScalaFunction
*/
public void registerFunction(String name, ScalarFunction function) {
functionCatalog.registerTempSystemScalarFunction(
name,
function);
}
在 Flink 提供的 System Function 中,我们已经提到,内置的 System Function 提供了包括数学、比较、字符串、聚合等常用功能,如果这些内置的 System Function 无法满足我们的需求,我们可以使用 Java、Scala 和 Python 语言自定义一个函数。接下来我们将将详细讲解如何自定义函数以及如何使用函数。
标量函数#
标量函数(Scalar Function)接收零个、一个或者多个输入,输出一个单值标量。这里以处理经纬度为例来展示如何自定义 Scala Function。
当前,大量的应用极度依赖地理信息(Geographic Information):打车软件需要用户用户定位起点和终点、外卖平台需要确定用户送餐地点、运动类 APP 会记录用户的活动轨迹等。我们一般使用精度(Longitude)和纬度(Latitude)来标记一个地点。经纬度作为原始数据很难直接拿来分析,需要做一些转化,而 Table API & SQL 中没有相应的函数,因此需要我们自己来实现。
如果想自定义函数,我们需要继承 org.apache.flink.table.functions.ScalarFunction 类,实现 eval 方法。这与第四章介绍的 DataStream API 中算子自定义有异曲同工之处。假设我们需要判断一个经纬度数据是否在北京四环以内,可以使用 Java 实现下面的函数:
public class IsInFourRing extends ScalarFunction {
// 北京四环经纬度范围
private static double LON_EAST = 116.48;
private static double LON_WEST = 116.27;
private static double LAT_NORTH = 39.988;
private static double LAT_SOUTH = 39.83;
// 判断输入的经纬度是否在四环内
public boolean eval(double lon, double lat) {
return !(lon > LON_EAST || lon < LON_WEST) &&
!(lat > LAT_NORTH || lat < LAT_SOUTH);
}
}
在这个实现中,eval 方法接收两个 double 类型的输入,对数据进行处理,生成一个 boolean 类型的输出。整个类中最重要的地方是 eval 方法,它决定了这个自定义函数的内在逻辑。自定义好函数之后,我们还需要用 registerFunction 方法将这个函数注册到 Catalog 中,并为之起名为 IsInFourRing,这样就可以在 SQL 语句中使用 IsInFourRing 的这个名字进行计算了。
List<Tuple4<Long, Double, Double, Timestamp>> geoList = new ArrayList<>();
geoList.add(Tuple4.of(1L, 116.2775, 39.91132, Timestamp.valueOf("2020-03-06 00:00:00")));
geoList.add(Tuple4.of(2L, 116.44095, 39.88319, Timestamp.valueOf("2020-03-06 00:00:01")));
geoList.add(Tuple4.of(3L, 116.25965, 39.90478, Timestamp.valueOf("2020-03-06 00:00:02")));
geoList.add(Tuple4.of(4L, 116.27054, 39.87869, Timestamp.valueOf("2020-03-06 00:00:03")));
DataStream<Tuple4<Long, Double, Double, Timestamp>> geoStream = env
.fromCollection(geoList)
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple4<Long, Double, Double, Timestamp>>() {
@Override
public long extractAscendingTimestamp(Tuple4<Long, Double, Double, Timestamp> element) {
return element.f3.getTime();
}
});
// 创建表
Table geoTable = tEnv.fromDataStream(geoStream, "id, long, alt, ts.rowtime, proc.proctime");
tEnv.createTemporaryView("geo", geoTable);
// 注册函数到 Catalog 中,指定名字为 IsInFourRing
tEnv.registerFunction("IsInFourRing", new IsInFourRing());
// 在 SQL 语句中使用 IsInFourRing 函数
Table inFourRingTab = tEnv.sqlQuery("SELECT id FROM geo WHERE IsInFourRing(long, alt)");
我们也可以利用编程语言的重载特性,针对不同类型的输入设计不同的函数。假如经纬度参数以 float 或者 String 形式传入,为了适应这些输入,可以实现多个 eval 方法,让编译器帮忙做重载:
public boolean eval(double lon, double lat) {
return !(lon > LON_EAST || lon < LON_WEST) &&
!(lat > LAT_NORTH || lat < LAT_SOUTH);
}
public boolean eval(float lon, float lat) {
return !(lon > LON_EAST || lon < LON_WEST) &&
!(lat > LAT_NORTH || lat < LAT_SOUTH);
}
public boolean eval(String lonStr, String latStr) {
double lon = Double.parseDouble(lonStr);
double lat = Double.parseDouble(latStr);
return !(lon > LON_EAST || lon < LON_WEST) &&
!(lat > LAT_NORTH || lat < LAT_SOUTH);
}
eval 方法的输入和输出类型决定了 ScalarFunction 的输入输出类型。在具体的执行过程中,Flink 的类型系统会自动推测输入和输出类型,一些无法被自动推测的类型可以使用 DataTypeHint 来提示 Flink 使用哪种输入输出类型。下面的代码接收两个 Timestamp 作为输入,返回两个时间戳之间的差,用 DataTypeHint 来提示将返回结果转化为 BIGINT 类型。
public class TimeDiff extends ScalarFunction {
public @DataTypeHint("BIGINT")long eval(Timestamp first, Timestamp second) {
return java.time.Duration.between(first.toInstant(), second.toInstant()).toMillis();
}
}
DataTypeHint 一般可以满足绝大多数的需求,如果类型仍然复杂,开发者可以自己重写 UserDefinedFunction#getTypeInference(DataTypeFactory) 方法,返回合适的类型。
表函数#
另一种常见的用户自定义函数为表函数(Table Function)。Table Function 能够接收零到多个标量输入,与 Scalar Function 不同的是,Table Function 输出零到多行,每行数据一到多列。从这些特征来看,Table Function 更像是一个表,一般出现在 FROM 之后。我们在 Temporal Table Join 中提到的 Temporal Table 就是一种 Table Function。
为了定义 Table Function,我们需要继承 org.apache.flink.table.functions.TableFunction 类,然后实现 eval 方法,这与 Scalar Function 几乎一致。同样,我们可以利用重载,实现一到多个 eval 方法。与 Scala Function 中只输出一个标量不同,Table Function 可以输出零到多行,eval 方法里使用 collect 方法将结果输出,输出的数据类型由 TableFunction<T> 中的泛型 T 决定。
下面的代码将字符串输入按照 # 切分,输出零到多行,输出类型为 String。
public class TableFunc extends TableFunction<String> {
// 按 #切分字符串,输出零到多行
public void eval(String str) {
if (str.contains("#")) {
String[] arr = str.split("#");
for (String i: arr) {
collect(i);
}
}
}
}
在主逻辑中,我们需要使用 registerFunction 方法注册函数,并指定一个名字。在 SQL 语句中,使用 LATERAL TABLE(<TableFunctionName>) 来调用这个 Table Function。
List<Tuple4<Integer, Long, String, Timestamp>> list = new ArrayList<>();
list.add(Tuple4.of(1, 1L, "Jack#22", Timestamp.valueOf("2020-03-06 00:00:00")));
list.add(Tuple4.of(2, 2L, "John#19", Timestamp.valueOf("2020-03-06 00:00:01")));
list.add(Tuple4.of(3, 3L, "nosharp", Timestamp.valueOf("2020-03-06 00:00:03")));
DataStream<Tuple4<Integer, Long, String, Timestamp>> stream = env
.fromCollection(list)
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple4<Integer, Long, String, Timestamp>>() {
@Override
public long extractAscendingTimestamp(Tuple4<Integer, Long, String, Timestamp> element) {
return element.f3.getTime();
}
});
// 获取 Table
Table table = tEnv.fromDataStream(stream, "id, long, str, ts.rowtime");
tEnv.createTemporaryView("input_table", table);
// 注册函数到 Catalog 中,指定名字为 Func
tEnv.registerFunction("Func", new TableFunc());
// input_table 与 LATERAL TABLE(Func(str)) 进行 JOIN
Table tableFunc = tEnv.sqlQuery("SELECT id, s FROM input_table, LATERAL TABLE(Func(str)) AS T(s)");
在这个例子中,LATERAL TABLE(Func(str)) 接受 input_table 中字段 str 作为输入,被命名为一个新表,名为 T,T 中有一个字段 s,s 是我们刚刚自定义的 TableFunc 的输出。本例中,input_table 和 LATERAL TABLE(Func(str)) 之间使用逗号 , 隔开,实际上这两个表是按照 CROSS JOIN 方式连接起来的,或者说,这两个表在做笛卡尔积,这个 SQL 语句返回值为:
1,22
1,Jack
2,19
2,John
我们也可以使用其他类型的 JOIN,比如 LEFT JOIN:
// input_table 与 LATERAL TABLE(Func(str)) 进行 LEFT JOIN
Table joinTableFunc = tEnv.sqlQuery("SELECT id, s FROM input_table LEFT JOIN LATERAL TABLE(Func(str)) AS T(s) ON TRUE");
ON TRUE 条件表示所有左侧表中的数据都与右侧进行 Join,因此结果中多出了一行 3,null。
1,22
1,Jack
2,19
2,John
3,null
聚合函数#
在 System Function 中我们曾介绍了聚合函数,聚合函数一般将多行数据进行聚合,输出一个标量。常用的聚合函数有 COUNT、SUM 等。对于一些特定问题,这些内置函数可能无法满足需求,在 Flink SQL 中,用户可以对聚合函数进行用户自定义,这种函数被称为用户自定义聚合函数(User-Defined Aggregate Function)。
假设我们的表中有下列字段:id、数值 v、权重 w,我们对 id 进行 GROUP BY,计算 v 的加权平均值。计算的过程如下表所示。
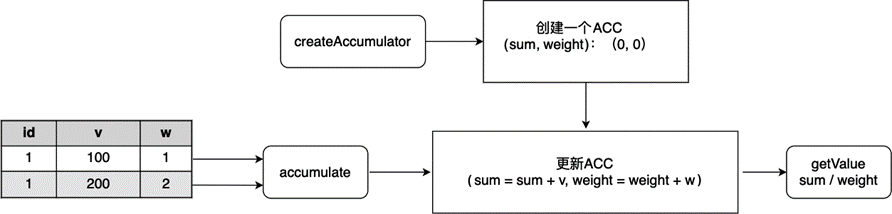
图 8.18 用户自定义聚合函数:求加权平均#
下面的代码实现了一个加权平均函数 WeightedAvg,这个函数接收两个 Long 类型的输入,返回一个 Double 类型的输出。计算过程基于累加器 WeightedAvgAccum,它记录了当前加权和 sum 以及权重 weight。
import org.apache.flink.table.functions.AggregateFunction;
import java.util.Iterator;
/**
* 加权平均函数
*/
public class WeightedAvg extends AggregateFunction<Double, WeightedAvg.WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
// 需要物化输出时,getValue 方法会被调用
@Override
public Double getValue(WeightedAvgAccum acc) {
if (acc.weight == 0) {
return null;
} else {
return (double) acc.sum / acc.weight;
}
}
// 新数据到达时,更新 ACC
public void accumulate(WeightedAvgAccum acc, long iValue, long iWeight) {
acc.sum += iValue * iWeight;
acc.weight += iWeight;
}
// 用于 BOUNDED OVER WINDOW,将较早的数据剔除
public void retract(WeightedAvgAccum acc, long iValue, long iWeight) {
acc.sum -= iValue * iWeight;
acc.weight -= iWeight;
}
// 将多个 ACC 合并为一个 ACC
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.weight += a.weight;
acc.sum += a.sum;
}
}
// 重置 ACC
public void resetAccumulator(WeightedAvgAccum acc) {
acc.weight = 0l;
acc.sum = 0l;
}
/**
* 累加器 Accumulator
* sum: 和
* weight: 权重
*/
public static class WeightedAvgAccum {
public long sum = 0;
public long weight = 0;
}
}
从这个例子我们可以看到,自定义聚合函数时,我们需要继承 org.apache.flink.table.functions.AggregateFunction 类。注意,这个类与 DataStream API 的窗口算子 中所介绍的 AggregateFunction 命名空间不同,在引用时不要写错。不过这两个 AggregateFunction 的工作原理大同小异。首先,AggregateFunction 调用 createAccumulator 方法创建一个累加器,这里简称 ACC,ACC 用来存储中间结果。接着,每当表中有新数据到达,Flink SQL 会调用 accumulate 方法,新数据会作用在 ACC 上,ACC 被更新。当一个分组的所有数据都被 accumulate 处理,getValue 方法可以将 ACC 中的中间结果输出。
综上,定义一个 AggregateFunction 时,这三个方法是必须实现的:
createAccumulator:创建 ACC,可以使用一个自定义的数据结构。accumulate:处理新流入数据,更新 ACC;第一个参数是 ACC,第二个以及以后的参数为流入数据。getValue:输出结果,返回值的数据类型 T 与AggregateFunction<T>中定义的泛型 T 保持一致。
createAccumulator 创建一个 ACC。accumulate 第一个参数为 ACC,第二个及以后的参数为整个 AggregateFunction 的输入参数,这个方法的作用就是接受输入,并将输入作用到 ACC 上,更新 ACC。getValue 返回值的类型 T 为整个 AggregateFunction<T> 的输出类型。
除了上面三个方法,下面三个方法需要根据使用情况来决定是否需要定义。例如,在流处理的会话窗口上进行聚合时,必须定义 merge 方法,因为当发现某行数据恰好可以将两个窗口连接为一个窗口时,merge 方法可以将两个窗口内的 ACC 合并。
retract:有界OVER WINDOW场景上,窗口是有界的,需要将早期的数据剔除。merge:将多个 ACC 合并为一个 ACC,常用在流处理的会话窗口分组和批处理分组上。resetAccumulator:重置 ACC,用于批处理分组上。
这些方法必须声明为 public,且不能是 static 的,方法名必须与上述名字保持一致。
在主逻辑中,我们注册这个函数,并在 SQL 语句中使用它:
List<Tuple4<Integer, Long, Long, Timestamp>> list = new ArrayList<>();
list.add(Tuple4.of(1, 100l, 1l, Timestamp.valueOf("2020-03-06 00:00:00")));
list.add(Tuple4.of(1, 200l, 2l, Timestamp.valueOf("2020-03-06 00:00:01")));
list.add(Tuple4.of(3, 300l, 3l, Timestamp.valueOf("2020-03-06 00:00:13")));
DataStream<Tuple4<Integer, Long, Long, Timestamp>> stream = env
.fromCollection(list)
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple4<Integer, Long, Long, Timestamp>>() {
@Override
public long extractAscendingTimestamp(Tuple4<Integer, Long, Long, Timestamp> element) {
return element.f3.getTime();
}
});
Table table = tEnv.fromDataStream(stream, "id, v, w, ts.rowtime");
tEnv.createTemporaryView("input_table", table);
tEnv.registerFunction("WeightAvg", new WeightedAvg());
Table agg = tEnv.sqlQuery("SELECT id, WeightAvg(v, w) FROM input_table GROUP BY id");